डीएनए संरचना: विशेषताएं, आरेख। डीएनए अणु की संरचना क्या है? डीएनए की संरचना, कार्य और गुण डीएनए अणु की संरचना और गुण
न्यूक्लिक एसिड जटिल, उच्च-आणविक बायोपॉलिमर हैं। ये पदार्थ सबसे पहले कोशिका केंद्रक में खोजे गए थे, इसलिए उनका नाम (लैटिन न्यूक्लियस से - न्यूक्लियस) पड़ा। बाद में यह पाया गया कि कोशिकाओं के साइटोप्लाज्म में न्यूक्लिक एसिड भी मौजूद होते हैं।
कई वैज्ञानिकों ने न्यूक्लिक एसिड की संरचना को समझने में भाग लिया, जैसे कि एफ. मिशर, ई. चार्गफ, आर. फ्रैंकलिन और अन्य, लेकिन अमेरिकी जैव रसायनज्ञ जे. वाटसन और अंग्रेजी आनुवंशिकीविद् एफ. क्रिक अंततः न्यूक्लिक एसिड की संरचना को हल करने में कामयाब रहे। 1953 में एसिड, जिसके लिए उन्हें नोबेल पुरस्कार से सम्मानित किया गया और उनकी खोज को 20वीं सदी की सबसे महान खोजों में से एक माना गया।
न्यूक्लिक एसिड दो प्रकार के होते हैं: डीएनए - डीऑक्सीराइबोन्यूक्लिक एसिडऔर आरएनए - राइबोन्यूक्लिक एसिड।उनके अणु पॉलिमर होते हैं जिनके मोनोमर्स न्यूक्लियोटाइड होते हैं। धागे जैसे डीएनए अणुओं की लंबाई बहुत अधिक होती है, मानव शरीर की कोशिकाओं में यह कई सेंटीमीटर होती है। मानव गुणसूत्रों के 26 जोड़े में डीएनए की कुल लंबाई लगभग 1.5 मीटर है। आरएनए अणु छोटे होते हैं - उनमें से प्रत्येक की लंबाई 0.01 मिमी से अधिक नहीं होती है।
न्यूक्लियोटाइड्स - न्यूक्लिक एसिड के मोनोमर्स, बदले में, एक जटिल संरचना रखते हैं। प्रत्येक न्यूक्लियोटाइड में तीन भाग होते हैं: एक नाइट्रोजनस बेस, एक साधारण पेंटोस कार्बोहाइड्रेट और एक फॉस्फोरिक एसिड अवशेष:
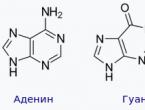
डीएनए न्यूक्लियोटाइड्स आरएनए न्यूक्लियोटाइड्स से संरचना में भिन्न होते हैं। डीएनए अणुओं में चार प्रकार के न्यूक्लियोटाइड होते हैं, जो नाइट्रोजनस आधारों में एक दूसरे से भिन्न होते हैं, जिनमें से ज्ञात हैं: एडेनिन, गुआनिन, साइटोसिन और थाइमिन। चार प्रकार के नाइट्रोजनस आधारों में से कौन सा डीएनए न्यूक्लियोटाइड का हिस्सा है, इसके आधार पर, इसे क्रमशः एडेनिन, गुआनिन, साइटोसिन या थाइमिन कहा जाता है। न्यूक्लियोटाइड्स को संक्षेप में ए, जी, सी, टी कहा जाता है। एक कार्बोहाइड्रेट जो एलएनए न्यूक्लियोटाइड्स का हिस्सा है। यह हमेशा एक जैसा होता है - यह डीऑक्सीराइबोज है; सभी डीएनए न्यूक्लियोटाइड का एक स्थिर और अपरिवर्तनीय घटक फॉस्फोरिक एसिड अवशेष है। इस प्रकार, डीएनए न्यूक्लियोटाइड्स में से एक, उदाहरण के लिए, एडेनिन ए, को योजनाबद्ध रूप से निम्नानुसार चित्रित किया जा सकता है:
न्यूक्लियोटाइड एक के डीऑक्सीराइबोज और उसके बाद के न्यूक्लियोटाइड के फॉस्फोरिक एसिड अवशेषों के बीच सहसंयोजक बंधन बनाकर एक श्रृंखला में जुड़ जाते हैं (चित्र 1)।
एक डीएनए अणु में एक नहीं, बल्कि न्यूक्लियोटाइड की दो श्रृंखलाएं होती हैं, जो नाइट्रोजनस आधारों द्वारा एक-दूसरे की ओर उन्मुख होती हैं और जिनके बीच हाइड्रोजन बंधन होते हैं। विभिन्न नाइट्रोजनस आधारों के बीच ऐसे बंधों की संख्या समान नहीं होती है, और परिणामस्वरूप, उन्हें केवल जोड़े में जोड़ा जा सकता है: एक पॉलीन्यूक्लियोटाइड श्रृंखला का नाइट्रोजनस आधार एडेनिन हमेशा दूसरी श्रृंखला के थाइमिन के साथ दो हाइड्रोजन बंधों द्वारा जुड़ा होता है, और गुआनिन - विपरीत पॉलीन्यूक्लियोटाइड श्रृंखला के नाइट्रोजनस बेस साइटोसिन के साथ तीन हाइड्रोजन बांड द्वारा। न्यूक्लियोटाइड को चयनात्मक रूप से संयोजित करने की इस क्षमता को कहा जाता है संपूरकता(लैटिन कॉम्प्लीमेंटम से - जोड़)।
चावल। 1. डीएनए की संरचना
अंतरिक्ष में, डीएनए अणु एक मुड़ा हुआ डबल हेलिक्स (डीएनए की द्वितीयक संरचना) है, जो बदले में, आगे स्थानिक पैकेजिंग से गुजरता है, जिससे एक तृतीयक संरचना बनती है - एक सुपरहेलिक्स। यह संरचना यूकेरियोटिक गुणसूत्रों के डीएनए की विशेषता है और डीएनए और परमाणु प्रोटीन के बीच बातचीत के कारण होती है। इस प्रकार, सबसे बड़े मानव गुणसूत्र के डीएनए की लंबाई 8 सेमी है, लेकिन साथ ही यह मुड़ जाता है ताकि, अंततः, यह 5 एनएम से अधिक न हो।
डीएनए अणु की मुख्य संपत्ति स्वयं-दोहराव करने की क्षमता है ( प्रतिकृति) (अंक 2)।
प्रतिकृति से पहले, डीएनए अणु का दोहरा हेलिक्स खुलता है और दो श्रृंखलाओं में टूट जाता है, जिनमें से प्रत्येक उस पर असेंबली के लिए मैट्रिक्स (फॉर्म) के रूप में कार्य करता है।
सिद्धांत संपूरकतानई (बच्ची) श्रृंखला। एक नई डीएनए श्रृंखला के निर्माण के लिए सामग्री न्यूक्लियोटाइड है, जो हमेशा स्वतंत्र अवस्था में नाभिक में मौजूद होते हैं। यह प्रक्रिया कोशिका विभाजन से पहले होती है और गुणसूत्रों की संख्या को दोगुना करने का आधार बनती है।
चावल। 2. डीएनए डबल हेलिक्स प्रतिकृति
डीएनए अणु के न्यूक्लियोटाइड प्रोटीन अणु में अमीनो एसिड के अनुक्रम को कूटबद्ध करते हैं - यह डीएनए का मुख्य कार्य है - वंशानुगत जानकारी संग्रहीत करना। एक प्रोटीन अणु में एक अमीनो एसिड एक डीएनए अणु के 3 न्यूक्लियोटाइड को एनकोड करता है। जीन डीएनए अणु का एक भाग है जिसमें एक प्रोटीन अणु का अमीनो एसिड अनुक्रम लिखा होता है।
इसकी रासायनिक संरचना के अनुसार, डीएनए ( डिऑक्सीराइबोन्यूक्लिक अम्ल) है जैव बहुलक, जिनके मोनोमर्स हैं न्यूक्लियोटाइड. यानी डीएनए है पॉलीन्यूक्लियोटाइड. इसके अलावा, एक डीएनए अणु में आम तौर पर एक पेचदार रेखा (जिसे अक्सर "हेलिकली ट्विस्टेड" कहा जाता है) के साथ एक दूसरे के सापेक्ष मुड़ी हुई दो श्रृंखलाएं होती हैं और हाइड्रोजन बांड द्वारा एक दूसरे से जुड़ी होती हैं।
जंजीरों को बाएँ और दाएँ (अक्सर) दोनों तरफ घुमाया जा सकता है।
कुछ वायरस में सिंगल स्ट्रैंड डीएनए होता है।
प्रत्येक डीएनए न्यूक्लियोटाइड में 1) एक नाइट्रोजनस बेस, 2) डीऑक्सीराइबोज़, 3) एक फॉस्फोरिक एसिड अवशेष होता है।
डबल दाएँ हाथ का डीएनए हेलिक्स
डीएनए की संरचना में निम्नलिखित शामिल हैं: एडीनाइन, गुआनिन, थाइमिनऔर साइटोसिन. एडेनिन और गुआनिन हैं प्यूरिन्स, और थाइमिन और साइटोसिन - को pyrimidines. कभी-कभी डीएनए में यूरैसिल होता है, जो आमतौर पर आरएनए की विशेषता है, जहां यह थाइमिन की जगह लेता है। 
एक डीएनए अणु की एक श्रृंखला के नाइट्रोजनस आधार दूसरे के नाइट्रोजनस आधारों से संपूरकता के सिद्धांत के अनुसार सख्ती से जुड़े होते हैं: एडेनिन केवल थाइमिन के साथ (एक दूसरे के साथ दो हाइड्रोजन बांड बनाते हैं), और ग्वानिन केवल साइटोसिन (तीन बांड) के साथ।

न्यूक्लियोटाइड में नाइट्रोजनस आधार स्वयं चक्रीय रूप के पहले कार्बन परमाणु से जुड़ा होता है डीऑक्सीराइबोज़, जो एक पेन्टोज़ (पांच कार्बन परमाणुओं वाला एक कार्बोहाइड्रेट) है। बंधन सहसंयोजक, ग्लाइकोसिडिक (सी-एन) है। राइबोज़ के विपरीत, डीऑक्सीराइबोज़ में इसके हाइड्रॉक्सिल समूहों में से एक का अभाव होता है। डीऑक्सीराइबोज़ वलय चार कार्बन परमाणुओं और एक ऑक्सीजन परमाणु से बनता है। पांचवां कार्बन परमाणु रिंग के बाहर है और ऑक्सीजन परमाणु के माध्यम से फॉस्फोरिक एसिड अवशेष से जुड़ा हुआ है। इसके अलावा, तीसरे कार्बन परमाणु पर ऑक्सीजन परमाणु के माध्यम से, पड़ोसी न्यूक्लियोटाइड का फॉस्फोरिक एसिड अवशेष जुड़ा होता है।

इस प्रकार, डीएनए के एक स्ट्रैंड में, आसन्न न्यूक्लियोटाइड डीऑक्सीराइबोज और फॉस्फोरिक एसिड (फॉस्फोडाइस्टर बॉन्ड) के बीच सहसंयोजक बंधन द्वारा एक दूसरे से जुड़े होते हैं। फॉस्फेट-डीऑक्सीराइबोज रीढ़ की हड्डी बनती है। इसके लंबवत निर्देशित, अन्य डीएनए श्रृंखला की ओर, नाइट्रोजनस आधार हैं, जो हाइड्रोजन बांड द्वारा दूसरी श्रृंखला के आधारों से जुड़े होते हैं।
डीएनए की संरचना ऐसी है कि हाइड्रोजन बांड से जुड़ी श्रृंखलाओं की रीढ़ अलग-अलग दिशाओं में निर्देशित होती है (वे कहते हैं "बहुदिशात्मक", "एंटीपैरेलल")। जिस तरफ एक डीऑक्सीराइबोज के पांचवें कार्बन परमाणु से जुड़े फॉस्फोरिक एसिड के साथ समाप्त होता है, वहीं दूसरा "मुक्त" तीसरे कार्बन परमाणु के साथ समाप्त होता है। अर्थात्, एक श्रृंखला का कंकाल दूसरे के सापेक्ष उल्टा हो जाता है। इस प्रकार, डीएनए श्रृंखलाओं की संरचना में, 5" सिरे और 3" सिरे प्रतिष्ठित होते हैं।
डीएनए प्रतिकृति (दोहरीकरण) के दौरान, नई श्रृंखलाओं का संश्लेषण हमेशा उनके 5वें सिरे से तीसरे सिरे तक होता है, क्योंकि नए न्यूक्लियोटाइड केवल मुक्त तीसरे सिरे में ही जोड़े जा सकते हैं।
अंततः (अप्रत्यक्ष रूप से आरएनए के माध्यम से), डीएनए श्रृंखला में हर तीन लगातार न्यूक्लियोटाइड एक प्रोटीन अमीनो एसिड के लिए कोड करते हैं।
डीएनए अणु की संरचना की खोज 1953 में एफ. क्रिक और डी. वाटसन के काम की बदौलत हुई (जिसे अन्य वैज्ञानिकों के शुरुआती काम से भी मदद मिली)। हालाँकि 19वीं सदी में डीएनए को एक रासायनिक पदार्थ के रूप में जाना जाता था। 20वीं सदी के 40 के दशक में यह स्पष्ट हो गया कि डीएनए आनुवंशिक जानकारी का वाहक है।
डबल हेलिक्स को डीएनए अणु की द्वितीयक संरचना माना जाता है। यूकेरियोटिक कोशिकाओं में, डीएनए की भारी मात्रा गुणसूत्रों में स्थित होती है, जहां यह प्रोटीन और अन्य पदार्थों से जुड़ा होता है, और अधिक सघनता से पैक भी होता है।
डीएनए अणु में दो स्ट्रैंड होते हैं जो एक डबल हेलिक्स बनाते हैं। इसकी संरचना को सबसे पहले 1953 में फ्रांसिस क्रिक और जेम्स वॉटसन ने समझा था।
सबसे पहले, डीएनए अणु, जिसमें एक दूसरे के चारों ओर मुड़ी हुई न्यूक्लियोटाइड श्रृंखलाओं की एक जोड़ी शामिल थी, ने इस सवाल को जन्म दिया कि इसका यह विशेष आकार क्यों है। वैज्ञानिक इस घटना को संपूरकता कहते हैं, जिसका अर्थ है कि केवल कुछ न्यूक्लियोटाइड ही इसके स्ट्रैंड में एक दूसरे के विपरीत पाए जा सकते हैं। उदाहरण के लिए, एडेनिन हमेशा थाइमिन के विपरीत होता है, और गुआनिन हमेशा साइटोसिन के विपरीत होता है। डीएनए अणु के इन न्यूक्लियोटाइड्स को पूरक कहा जाता है।
योजनाबद्ध रूप से इसे इस प्रकार दर्शाया गया है:
टी-ए
सी - जी
ये जोड़े एक रासायनिक न्यूक्लियोटाइड बंधन बनाते हैं, जो अमीनो एसिड का क्रम निर्धारित करता है। पहले मामले में यह थोड़ा कमजोर है. C और G के बीच संबंध अधिक मजबूत है. गैर-पूरक न्यूक्लियोटाइड एक दूसरे के साथ जोड़े नहीं बनाते हैं।
भवन के बारे में
अतः डीएनए अणु की संरचना विशेष होती है। इसका यह आकार एक कारण से है: तथ्य यह है कि न्यूक्लियोटाइड की संख्या बहुत बड़ी है, और लंबी श्रृंखलाओं को समायोजित करने के लिए बहुत अधिक जगह की आवश्यकता होती है। यही कारण है कि जंजीरों की विशेषता एक सर्पिल मोड़ है। इस घटना को स्पाइरलाइजेशन कहा जाता है, यह धागों को लगभग पांच से छह गुना छोटा करने की अनुमति देता है।
शरीर इस प्रकार के कुछ अणुओं का बहुत सक्रिय रूप से उपयोग करता है, अन्य का शायद ही कभी। उत्तरार्द्ध, स्पाइरलाइज़ेशन के अलावा, सुपरस्पिरलाइज़ेशन जैसी "कॉम्पैक्ट पैकेजिंग" से भी गुजरता है। और फिर डीएनए अणु की लंबाई 25-30 गुना कम हो जाती है।

किसी अणु की "पैकेजिंग" क्या है?
सुपरकोइलिंग की प्रक्रिया में हिस्टोन प्रोटीन शामिल होते हैं। उनकी संरचना और स्वरूप धागे के स्पूल या छड़ी की तरह है। उन पर सर्पिल धागे लपेटे जाते हैं, जो तुरंत "कॉम्पैक्टली पैक" हो जाते हैं और बहुत कम जगह लेते हैं। जब एक या दूसरे धागे का उपयोग करने की आवश्यकता होती है, तो इसे स्पूल से खोल दिया जाता है, उदाहरण के लिए, हिस्टोन प्रोटीन, और हेलिक्स दो समानांतर श्रृंखलाओं में खुल जाता है। जब डीएनए अणु इस अवस्था में होता है, तो उससे आवश्यक आनुवंशिक डेटा पढ़ा जा सकता है। हालांकि, एक शर्त है। जानकारी प्राप्त करना तभी संभव है जब डीएनए अणु की संरचना बिना मुड़े हुए आकार की हो। पढ़ने के लिए सुलभ क्रोमोसोम को यूक्रोमैटिन कहा जाता है, और यदि वे सुपरकोइल्ड हैं, तो वे पहले से ही हेटरोक्रोमैटिन हैं।
न्यूक्लिक एसिड
न्यूक्लिक एसिड, प्रोटीन की तरह, बायोपॉलिमर हैं। मुख्य कार्य वंशानुगत (आनुवंशिक जानकारी) का भंडारण, कार्यान्वयन और प्रसारण है। वे दो प्रकार में आते हैं: डीएनए और आरएनए (डीऑक्सीराइबोन्यूक्लिक और राइबोन्यूक्लिक)। उनमें मोनोमर्स न्यूक्लियोटाइड होते हैं, जिनमें से प्रत्येक में एक फॉस्फोरिक एसिड अवशेष, एक पांच-कार्बन चीनी (डीऑक्सीराइबोज/राइबोज) और एक नाइट्रोजनस बेस होता है। डीएनए कोड में 4 प्रकार के न्यूक्लियोटाइड शामिल हैं - एडेनिन (ए) / गुआनिन (जी) / साइटोसिन (सी) / थाइमिन (टी)। उनमें मौजूद नाइट्रोजन आधार में भिन्नता होती है।
एक डीएनए अणु में, न्यूक्लियोटाइड की संख्या बहुत बड़ी हो सकती है - कई हजार से लेकर दसियों और लाखों तक। ऐसे विशाल अणुओं की जांच इलेक्ट्रॉन माइक्रोस्कोप से की जा सकती है। इस मामले में, आप पॉलीन्यूक्लियोटाइड स्ट्रैंड्स की एक दोहरी श्रृंखला देख पाएंगे, जो न्यूक्लियोटाइड्स के नाइट्रोजनस आधारों के हाइड्रोजन बांड द्वारा एक दूसरे से जुड़े हुए हैं।

अनुसंधान
शोध के दौरान वैज्ञानिकों ने पाया कि विभिन्न जीवित जीवों में डीएनए अणुओं के प्रकार भिन्न-भिन्न होते हैं। यह भी पाया गया कि एक श्रृंखला का गुआनिन केवल साइटोसिन से बंध सकता है, और थाइमिन एडेनिन से। एक श्रृंखला में न्यूक्लियोटाइड की व्यवस्था सख्ती से समानांतर से मेल खाती है। पॉलीन्यूक्लियोटाइड्स की इस पूरकता के लिए धन्यवाद, डीएनए अणु दोगुना और आत्म-प्रजनन करने में सक्षम है। लेकिन सबसे पहले, पूरक श्रृंखलाएं, विशेष एंजाइमों के प्रभाव में जो युग्मित न्यूक्लियोटाइड को नष्ट करती हैं, अलग हो जाती हैं, और फिर उनमें से प्रत्येक में लापता श्रृंखला का संश्लेषण शुरू होता है। ऐसा प्रत्येक कोशिका में बड़ी मात्रा में मौजूद मुक्त न्यूक्लियोटाइड के कारण होता है। इसके परिणामस्वरूप, "माँ अणु" के बजाय, दो "बेटी" अणु बनते हैं, जो संरचना और संरचना में समान होते हैं, और डीएनए कोड मूल बन जाता है। यह प्रक्रिया कोशिका विभाजन का अग्रदूत है। यह मातृ कोशिकाओं से बेटी कोशिकाओं, साथ ही बाद की सभी पीढ़ियों तक सभी वंशानुगत डेटा के संचरण को सुनिश्चित करता है।
जीन कोड कैसे पढ़ा जाता है?
आज, न केवल डीएनए अणु के द्रव्यमान की गणना की जाती है - बल्कि अधिक जटिल डेटा का पता लगाना भी संभव है जो पहले वैज्ञानिकों के लिए दुर्गम था। उदाहरण के लिए, आप इस बारे में जानकारी पढ़ सकते हैं कि कोई जीव अपनी कोशिका का उपयोग कैसे करता है। बेशक, सबसे पहले यह जानकारी एन्कोडेड रूप में होती है और इसमें एक निश्चित मैट्रिक्स का रूप होता है, और इसलिए इसे एक विशेष वाहक तक पहुंचाया जाना चाहिए, जो कि आरएनए है। राइबोन्यूक्लिक एसिड परमाणु झिल्ली के माध्यम से कोशिका में प्रवेश करने और अंदर एन्कोडेड जानकारी को पढ़ने में सक्षम है। इस प्रकार, आरएनए नाभिक से कोशिका तक छिपे हुए डेटा का वाहक है, और यह डीएनए से इस मायने में भिन्न है कि इसमें डीऑक्सीराइबोज़ के बजाय राइबोज़ और थाइमिन के बजाय यूरैसिल होता है। इसके अलावा, आरएनए एकल-फंसे हुए है।

आरएनए संश्लेषण
डीएनए के गहन विश्लेषण से पता चला है कि आरएनए नाभिक छोड़ने के बाद, साइटोप्लाज्म में प्रवेश करता है, जहां इसे राइबोसोम (विशेष एंजाइम सिस्टम) में मैट्रिक्स के रूप में एकीकृत किया जा सकता है। प्राप्त जानकारी से निर्देशित होकर, वे प्रोटीन अमीनो एसिड के उचित अनुक्रम को संश्लेषित कर सकते हैं। राइबोसोम त्रिक कोड से सीखता है कि किस प्रकार के कार्बनिक यौगिक को बनाने वाली प्रोटीन श्रृंखला से जोड़ा जाना चाहिए। प्रत्येक अमीनो एसिड का अपना विशिष्ट त्रिक होता है, जो इसे एनकोड करता है।
श्रृंखला का निर्माण पूरा होने के बाद, यह एक विशिष्ट स्थानिक रूप प्राप्त कर लेता है और एक प्रोटीन में बदल जाता है जो अपने हार्मोनल, निर्माण, एंजाइमेटिक और अन्य कार्य करने में सक्षम होता है। किसी भी जीव के लिए यह एक जीन उत्पाद है। इसी से जीन के सभी प्रकार के गुण, गुण और अभिव्यक्तियाँ निर्धारित होती हैं।

जीन
अनुक्रमण प्रक्रियाएं मुख्य रूप से यह जानकारी प्राप्त करने के लिए विकसित की गईं कि डीएनए अणु की संरचना में कितने जीन हैं। और, हालाँकि शोध ने वैज्ञानिकों को इस मामले में बड़ी प्रगति करने की अनुमति दी है, लेकिन उनकी सटीक संख्या जानना अभी भी संभव नहीं है।
कुछ साल पहले यह माना गया था कि डीएनए अणुओं में लगभग 100 हजार जीन होते हैं। कुछ समय बाद यह आंकड़ा घटकर 80 हजार हो गया और 1998 में आनुवंशिकीविदों ने बताया कि एक डीएनए में केवल 50 हजार जीन मौजूद होते हैं, जो कुल डीएनए लंबाई का केवल 3% है। लेकिन आनुवंशिकीविदों के नवीनतम निष्कर्ष चौंकाने वाले थे। अब उनका दावा है कि जीनोम में इनमें से 25-40 हजार इकाइयां शामिल हैं। यह पता चला है कि क्रोमोसोमल डीएनए का केवल 1.5% प्रोटीन कोडिंग के लिए जिम्मेदार है।
शोध यहीं नहीं रुका। जेनेटिक इंजीनियरिंग विशेषज्ञों की एक समानांतर टीम ने पाया कि एक अणु में जीन की संख्या ठीक 32 हजार है। जैसा कि आप देख सकते हैं, निश्चित उत्तर पाना अभी भी असंभव है। बहुत सारे विरोधाभास हैं. सभी शोधकर्ता केवल अपने परिणामों पर भरोसा करते हैं।
क्या वहां विकास हुआ था?
इस तथ्य के बावजूद कि अणु के विकास का कोई सबूत नहीं है (चूंकि डीएनए अणु की संरचना नाजुक और आकार में छोटी है), वैज्ञानिकों ने अभी भी एक धारणा बनाई है। प्रयोगशाला के आंकड़ों के आधार पर, उन्होंने निम्नलिखित संस्करण को आवाज दी: अपनी उपस्थिति के प्रारंभिक चरण में, अणु में एक सरल स्व-प्रतिकृति पेप्टाइड का रूप था, जिसमें प्राचीन महासागरों में पाए जाने वाले 32 अमीनो एसिड शामिल थे।
स्व-प्रतिकृति के बाद, प्राकृतिक चयन की शक्तियों के कारण, अणुओं ने बाहरी तत्वों से खुद को बचाने की क्षमता हासिल कर ली। वे अधिक समय तक जीवित रहने लगे और बड़ी मात्रा में प्रजनन करने लगे। जिन अणुओं ने खुद को लिपिड बुलबुले में पाया, उनके पास खुद को पुन: उत्पन्न करने का हर मौका था। क्रमिक चक्रों की एक श्रृंखला के परिणामस्वरूप, लिपिड बुलबुले ने कोशिका झिल्ली का रूप प्राप्त कर लिया, और फिर - प्रसिद्ध कणों का। यह ध्यान दिया जाना चाहिए कि आज डीएनए अणु का कोई भी भाग एक जटिल और स्पष्ट रूप से कार्य करने वाली संरचना है, जिसकी सभी विशेषताओं का वैज्ञानिकों ने अभी तक पूरी तरह से अध्ययन नहीं किया है।

आधुनिक दुनिया
हाल ही में इजराइल के वैज्ञानिकों ने एक ऐसा कंप्यूटर विकसित किया है जो प्रति सेकंड खरबों ऑपरेशन कर सकता है। आज यह पृथ्वी पर सबसे तेज़ कार है। पूरा रहस्य यह है कि नवोन्मेषी उपकरण डीएनए द्वारा संचालित है। प्रोफेसरों का कहना है कि निकट भविष्य में ऐसे कंप्यूटर ऊर्जा भी पैदा करने में सक्षम होंगे।
एक साल पहले, रेहोवोट (इज़राइल) में वीज़मैन इंस्टीट्यूट के विशेषज्ञों ने अणुओं और एंजाइमों से युक्त एक प्रोग्राम योग्य आणविक कंप्यूटिंग मशीन के निर्माण की घोषणा की थी। उन्होंने सिलिकॉन माइक्रोचिप्स को उनके साथ बदल दिया। आज तक, टीम ने और प्रगति की है। अब केवल एक डीएनए अणु एक कंप्यूटर को आवश्यक डेटा और आवश्यक ईंधन प्रदान कर सकता है।
जैव रासायनिक "नैनो कंप्यूटर" कोई कल्पना नहीं है; वे पहले से ही प्रकृति में मौजूद हैं और हर जीवित प्राणी में प्रकट होते हैं। लेकिन अक्सर इन्हें लोगों द्वारा प्रबंधित नहीं किया जाता है। कोई व्यक्ति "पाई" संख्या की गणना करने के लिए अभी तक किसी भी पौधे के जीनोम पर काम नहीं कर सकता है।
डेटा भंडारण/प्रसंस्करण के लिए डीएनए का उपयोग करने का विचार पहली बार 1994 में वैज्ञानिकों के दिमाग में आया था। यह तब था जब एक सरल गणितीय समस्या को हल करने के लिए एक अणु का उपयोग किया गया था। तब से, कई शोध समूहों ने डीएनए कंप्यूटर से संबंधित विभिन्न परियोजनाओं का प्रस्ताव दिया है। लेकिन यहां सभी प्रयास केवल ऊर्जा अणु पर आधारित थे। ऐसे कंप्यूटर को आप नंगी आंखों से नहीं देख सकते, यह टेस्ट ट्यूब में पानी के पारदर्शी घोल जैसा दिखता है। इसमें कोई यांत्रिक भाग नहीं हैं, बल्कि केवल खरबों जैव-आणविक उपकरण हैं - और यह केवल तरल की एक बूंद में है!
मानव डीएनए
लोग मानव डीएनए के प्रकार के बारे में 1953 में जागरूक हुए, जब वैज्ञानिक पहली बार दुनिया को डबल-स्ट्रैंडेड डीएनए मॉडल प्रदर्शित करने में सक्षम हुए। इसके लिए किर्क और वॉटसन को नोबेल पुरस्कार मिला, क्योंकि यह खोज 20वीं सदी में मौलिक हो गई थी।
समय के साथ, निश्चित रूप से, उन्होंने साबित कर दिया कि एक संरचित मानव अणु न केवल प्रस्तावित संस्करण जैसा दिख सकता है। अधिक विस्तृत डीएनए विश्लेषण करने के बाद, उन्होंने ए-, बी- और बाएं हाथ के फॉर्म जेड- की खोज की। फॉर्म ए- अक्सर एक अपवाद होता है, क्योंकि यह नमी की कमी होने पर ही बनता है। लेकिन यह केवल प्रयोगशाला अध्ययनों में ही संभव है; प्राकृतिक वातावरण के लिए यह असामान्य है; ऐसी प्रक्रिया जीवित कोशिका में नहीं हो सकती है।
बी-आकार क्लासिक है और इसे डबल दाएं हाथ की श्रृंखला के रूप में जाना जाता है, लेकिन जेड-आकार न केवल बाईं ओर विपरीत दिशा में मुड़ा हुआ है, बल्कि इसमें अधिक ज़िगज़ैग उपस्थिति भी है। वैज्ञानिकों ने जी-क्वाड्रुप्लेक्स रूप की भी पहचान कर ली है। इसकी संरचना में 2 नहीं, बल्कि 4 धागे हैं। आनुवंशिकीविदों के अनुसार यह रूप उन क्षेत्रों में होता है जहां ग्वानिन की अधिक मात्रा होती है।

कृत्रिम डीएनए
आज पहले से ही कृत्रिम डीएनए मौजूद है, जो असली की एक समान प्रतिलिपि है; यह पूरी तरह से प्राकृतिक डबल हेलिक्स की संरचना का अनुसरण करता है। लेकिन, मूल पॉलीन्यूक्लियोटाइड के विपरीत, कृत्रिम में केवल दो अतिरिक्त न्यूक्लियोटाइड होते हैं।
चूंकि डबिंग वास्तविक डीएनए के विभिन्न अध्ययनों से प्राप्त जानकारी के आधार पर बनाई गई थी, इसलिए इसे कॉपी, स्व-प्रतिकृति और विकसित भी किया जा सकता है। विशेषज्ञ ऐसे कृत्रिम अणु के निर्माण पर लगभग 20 वर्षों से काम कर रहे हैं। परिणाम एक अद्भुत आविष्कार है जो प्राकृतिक डीएनए की तरह ही आनुवंशिक कोड का उपयोग कर सकता है।
चार मौजूदा नाइट्रोजनस आधारों में, आनुवंशिकीविदों ने दो अतिरिक्त आधार जोड़े, जो प्राकृतिक आधारों के रासायनिक संशोधन द्वारा बनाए गए थे। प्राकृतिक डीएनए के विपरीत, कृत्रिम डीएनए काफी छोटा निकला। इसमें केवल 81 आधार जोड़े हैं। हालाँकि, यह प्रजनन और विकास भी करता है।
कृत्रिम रूप से प्राप्त अणु की प्रतिकृति पोलीमरेज़ श्रृंखला प्रतिक्रिया के कारण होती है, लेकिन अभी तक यह स्वतंत्र रूप से नहीं, बल्कि वैज्ञानिकों के हस्तक्षेप से होता है। वे स्वतंत्र रूप से उक्त डीएनए में आवश्यक एंजाइम जोड़ते हैं, इसे विशेष रूप से तैयार तरल माध्यम में रखते हैं।
अंतिम परिणाम
डीएनए विकास की प्रक्रिया और अंतिम परिणाम उत्परिवर्तन जैसे विभिन्न कारकों से प्रभावित हो सकते हैं। इससे पदार्थ के नमूनों का अध्ययन करना आवश्यक हो जाता है ताकि विश्लेषण परिणाम विश्वसनीय और विश्वसनीय हो। एक उदाहरण पितृत्व परीक्षण है. लेकिन हम इस बात से खुश हुए बिना नहीं रह सकते कि उत्परिवर्तन जैसी घटनाएं दुर्लभ हैं। फिर भी, विश्लेषण के आधार पर अधिक सटीक जानकारी प्राप्त करने के लिए पदार्थ के नमूनों की हमेशा दोबारा जाँच की जाती है।

प्लांट डीएनए
उच्च अनुक्रमण प्रौद्योगिकियों (एचटीएस) के लिए धन्यवाद, जीनोमिक्स के क्षेत्र में एक क्रांति हुई है - पौधों से डीएनए निष्कर्षण भी संभव है। बेशक, पौधों की सामग्री से उच्च गुणवत्ता वाले आणविक भार डीएनए प्राप्त करने में माइटोकॉन्ड्रिया और क्लोरोप्लास्ट डीएनए की बड़ी संख्या के साथ-साथ पॉलीसेकेराइड और फेनोलिक यौगिकों के उच्च स्तर के कारण कुछ कठिनाइयां पैदा होती हैं। इस मामले में हम जिस संरचना पर विचार कर रहे हैं उसे अलग करने के लिए विभिन्न तरीकों का उपयोग किया जाता है।
डीएनए में हाइड्रोजन बंधन
डीएनए अणु में हाइड्रोजन बंधन एक धनात्मक आवेशित हाइड्रोजन परमाणु के बीच उत्पन्न विद्युत चुम्बकीय आकर्षण के लिए जिम्मेदार होता है जो एक विद्युत ऋणात्मक परमाणु से जुड़ा होता है। यह द्विध्रुवीय अंतःक्रिया रासायनिक बंधन की कसौटी पर खरी नहीं उतरती। लेकिन यह अंतरआण्विक रूप से या अणु के विभिन्न भागों में, यानी इंट्रामोल्युलर रूप से हो सकता है।

एक हाइड्रोजन परमाणु विद्युत ऋणात्मक परमाणु से जुड़ता है जो बंधन का दाता है। एक विद्युत ऋणात्मक परमाणु नाइट्रोजन, फ्लोरीन या ऑक्सीजन हो सकता है। यह - विकेंद्रीकरण के माध्यम से - हाइड्रोजन नाभिक से इलेक्ट्रॉन बादल को अपनी ओर आकर्षित करता है और हाइड्रोजन परमाणु (आंशिक रूप से) को सकारात्मक रूप से चार्ज करता है। चूँकि H का आकार अन्य अणुओं और परमाणुओं की तुलना में छोटा है, इसलिए आवेश भी छोटा है।
डीएनए डिकोडिंग
डीएनए अणु को समझने से पहले, वैज्ञानिक पहले बड़ी संख्या में कोशिकाएं लेते हैं। सबसे सटीक और सफल कार्य के लिए, उनमें से लगभग दस लाख की आवश्यकता होती है। अध्ययन के दौरान प्राप्त परिणामों की लगातार तुलना की जाती है और उन्हें रिकॉर्ड किया जाता है। आज, जीनोम डिकोडिंग अब दुर्लभ नहीं है, बल्कि एक सुलभ प्रक्रिया है।

बेशक, किसी एकल कोशिका के जीनोम को समझना एक अव्यावहारिक अभ्यास है। ऐसे अध्ययनों के दौरान प्राप्त आंकड़ों में वैज्ञानिकों की कोई दिलचस्पी नहीं है। लेकिन यह समझना महत्वपूर्ण है कि वर्तमान में मौजूद सभी डिकोडिंग विधियां, उनकी जटिलता के बावजूद, पर्याप्त प्रभावी नहीं हैं। वे डीएनए का केवल 40-70% ही पढ़ने की अनुमति देंगे।
हालाँकि, हार्वर्ड के प्रोफेसरों ने हाल ही में एक ऐसी विधि की घोषणा की जिसके माध्यम से 90% जीनोम को समझा जा सकता है। यह तकनीक पृथक कोशिकाओं में प्राइमर अणुओं को जोड़ने पर आधारित है, जिसकी मदद से डीएनए प्रतिकृति शुरू होती है। लेकिन फिर भी इस पद्धति को सफल नहीं माना जा सकता; विज्ञान में खुले तौर पर उपयोग करने से पहले इसे अभी भी परिष्कृत करने की आवश्यकता है।
दाईं ओर वर्ना (बुल्गारिया) में समुद्र तट पर लोगों से निर्मित मानव डीएनए का सबसे बड़ा हेलिक्स है, जिसे 23 अप्रैल, 2016 को गिनीज बुक ऑफ रिकॉर्ड्स में शामिल किया गया है।
डिऑक्सीराइबोन्यूक्लिक अम्ल। सामान्य जानकारी
डीएनए (डीऑक्सीराइबोन्यूक्लिक एसिड) जीवन का एक प्रकार का खाका है, एक जटिल कोड जिसमें वंशानुगत जानकारी पर डेटा होता है। यह जटिल मैक्रोमोलेक्यूल वंशानुगत आनुवंशिक जानकारी को पीढ़ी-दर-पीढ़ी संग्रहीत और प्रसारित करने में सक्षम है। डीएनए किसी भी जीवित जीव के आनुवंशिकता और परिवर्तनशीलता जैसे गुणों को निर्धारित करता है। इसमें एन्कोड की गई जानकारी किसी भी जीवित जीव के संपूर्ण विकास कार्यक्रम को निर्धारित करती है। आनुवंशिक रूप से निर्धारित कारक किसी व्यक्ति और किसी अन्य जीव दोनों के जीवन के संपूर्ण पाठ्यक्रम को पूर्व निर्धारित करते हैं। बाहरी वातावरण के कृत्रिम या प्राकृतिक प्रभाव व्यक्तिगत आनुवंशिक लक्षणों की समग्र अभिव्यक्ति को थोड़ा सा ही प्रभावित कर सकते हैं या क्रमादेशित प्रक्रियाओं के विकास को प्रभावित कर सकते हैं।
डिऑक्सीराइबोन्यूक्लिक अम्ल(डीएनए) एक मैक्रोमोलेक्यूल है (तीन मुख्य में से एक, अन्य दो आरएनए और प्रोटीन हैं) जो भंडारण, पीढ़ी से पीढ़ी तक संचरण और जीवित जीवों के विकास और कामकाज के लिए आनुवंशिक कार्यक्रम के कार्यान्वयन को सुनिश्चित करता है। डीएनए में विभिन्न प्रकार के आरएनए और प्रोटीन की संरचना के बारे में जानकारी होती है।
यूकेरियोटिक कोशिकाओं (जानवरों, पौधों और कवक) में, डीएनए कोशिका नाभिक में गुणसूत्रों के हिस्से के साथ-साथ कुछ सेलुलर ऑर्गेनेल (माइटोकॉन्ड्रिया और प्लास्टिड्स) में पाया जाता है। प्रोकैरियोटिक जीवों (बैक्टीरिया और आर्किया) की कोशिकाओं में, एक गोलाकार या रैखिक डीएनए अणु, तथाकथित न्यूक्लियॉइड, अंदर से कोशिका झिल्ली से जुड़ा होता है। उनमें और निचले यूकेरियोट्स (उदाहरण के लिए, यीस्ट) में, छोटे स्वायत्त, मुख्य रूप से गोलाकार डीएनए अणु जिन्हें प्लास्मिड कहा जाता है, भी पाए जाते हैं।
रासायनिक दृष्टिकोण से, डीएनए एक लंबा बहुलक अणु है जिसमें न्यूक्लियोटाइड्स नामक दोहराए जाने वाले ब्लॉक होते हैं। प्रत्येक न्यूक्लियोटाइड में एक नाइट्रोजनस बेस, एक शर्करा (डीऑक्सीराइबोज) और एक फॉस्फेट समूह होता है। श्रृंखला में न्यूक्लियोटाइड के बीच के बंधन डीऑक्सीराइबोज़ द्वारा बनते हैं ( साथ) और फॉस्फेट ( एफ) समूह (फॉस्फोडाइस्टर बांड)।

चावल। 2. न्यूक्लियोटाइड में एक नाइट्रोजनस बेस, एक शर्करा (डीऑक्सीराइबोज) और एक फॉस्फेट समूह होता है
अधिकांश मामलों में (एकल-फंसे डीएनए वाले कुछ वायरस को छोड़कर), डीएनए मैक्रोमोलेक्यूल में एक दूसरे की ओर नाइट्रोजनस आधारों के साथ उन्मुख दो श्रृंखलाएं होती हैं। यह डबल-स्ट्रैंडेड अणु एक हेलिक्स के साथ मुड़ा हुआ है।
डीएनए में चार प्रकार के नाइट्रोजनस आधार पाए जाते हैं (एडेनिन, गुआनिन, थाइमिन और साइटोसिन)। एक श्रृंखला के नाइट्रोजनस आधार पूरकता के सिद्धांत के अनुसार हाइड्रोजन बांड द्वारा दूसरी श्रृंखला के नाइट्रोजनस आधारों से जुड़े होते हैं: एडेनिन केवल थाइमिन के साथ जुड़ता है ( पर), गुआनिन - केवल साइटोसिन के साथ ( जी-सी). यह ये जोड़े हैं जो डीएनए सर्पिल "सीढ़ी" के " पायदान " बनाते हैं (देखें: चित्र 2, 3 और 4)।

चावल। 2. नाइट्रोजनी क्षार
न्यूक्लियोटाइड्स का अनुक्रम आपको विभिन्न प्रकार के आरएनए के बारे में जानकारी को "एनकोड" करने की अनुमति देता है, जिनमें से सबसे महत्वपूर्ण मैसेंजर या टेम्पलेट (एमआरएनए), राइबोसोमल (आरआरएनए) और ट्रांसपोर्ट (टीआरएनए) हैं। इन सभी प्रकार के आरएनए को प्रतिलेखन के दौरान संश्लेषित आरएनए अनुक्रम में डीएनए अनुक्रम की प्रतिलिपि बनाकर डीएनए टेम्पलेट पर संश्लेषित किया जाता है, और प्रोटीन जैवसंश्लेषण (अनुवाद प्रक्रिया) में भाग लेते हैं। कोडिंग अनुक्रमों के अलावा, सेल डीएनए में ऐसे अनुक्रम होते हैं जो विनियामक और संरचनात्मक कार्य करते हैं।

चावल। 3. डीएनए प्रतिकृति
डीएनए रासायनिक यौगिकों के बुनियादी संयोजनों की व्यवस्था और इन संयोजनों के बीच मात्रात्मक संबंध वंशानुगत जानकारी की कोडिंग सुनिश्चित करते हैं।
शिक्षा नया डीएनए (प्रतिकृति)
- प्रतिकृति प्रक्रिया: डीएनए डबल हेलिक्स को खोलना - डीएनए पोलीमरेज़ द्वारा पूरक स्ट्रैंड का संश्लेषण - एक से दो डीएनए अणुओं का निर्माण।
- जब एंजाइम रासायनिक यौगिकों के आधार जोड़े के बीच के बंधन को तोड़ देते हैं तो डबल हेलिक्स दो शाखाओं में "अनज़िप" हो जाता है।
- प्रत्येक शाखा नए डीएनए का एक तत्व है। नए आधार जोड़े मूल शाखा के समान क्रम में जुड़े हुए हैं।
दोहराव के पूरा होने पर, दो स्वतंत्र हेलिकॉप्टर बनते हैं, जो मूल डीएनए के रासायनिक यौगिकों से बने होते हैं और समान आनुवंशिक कोड वाले होते हैं। इस तरह, डीएनए एक कोशिका से दूसरी कोशिका तक जानकारी पहुंचाने में सक्षम होता है।
अधिक विस्तृत जानकारी:
न्यूक्लिक एसिड की संरचना

चावल। 4 . नाइट्रोजन आधार: एडेनिन, गुआनिन, साइटोसिन, थाइमिन
डिऑक्सीराइबोन्यूक्लिक अम्ल(डीएनए) न्यूक्लिक एसिड को संदर्भित करता है। न्यूक्लिक एसिडअनियमित बायोपॉलिमरों का एक वर्ग है जिनके मोनोमर्स न्यूक्लियोटाइड हैं।
न्यूक्लियोटाइडसे बना हुआ नाइट्रोजन बेस, पांच-कार्बन कार्बोहाइड्रेट (पेंटोज़) से जुड़ा - डीऑक्सीराइबोज़(डीएनए के मामले में) या राइबोज़(आरएनए के मामले में), जो फॉस्फोरिक एसिड अवशेष (एच 2 पीओ 3 -) के साथ जुड़ता है।
नाइट्रोजनी आधारदो प्रकार के होते हैं: पाइरीमिडीन बेस - यूरैसिल (केवल आरएनए में), साइटोसिन और थाइमिन, प्यूरीन बेस - एडेनिन और गुआनिन।

चावल। 5. न्यूक्लियोटाइड्स की संरचना (बाएं), डीएनए में न्यूक्लियोटाइड का स्थान (नीचे) और नाइट्रोजनस आधारों के प्रकार (दाएं): पाइरीमिडीन और प्यूरीन

पेंटोज़ अणु में कार्बन परमाणुओं की संख्या 1 से 5 तक होती है। फॉस्फेट तीसरे और पांचवें कार्बन परमाणुओं के साथ जुड़ता है। इस प्रकार न्यूक्लिनोटाइड्स को न्यूक्लिक एसिड श्रृंखला में संयोजित किया जाता है। इस प्रकार, हम डीएनए स्ट्रैंड के 3' और 5' सिरों को अलग कर सकते हैं:

चावल। 6. डीएनए श्रृंखला के 3' और 5' सिरों का अलगाव
डीएनए के दो स्ट्रैंड बनते हैं दोहरी कुंडली. सर्पिल में ये शृंखलाएँ विपरीत दिशाओं में उन्मुख होती हैं। डीएनए के विभिन्न स्ट्रैंड में, नाइट्रोजनस आधार एक दूसरे से जुड़े होते हैं हाइड्रोजन बांड. एडेनिन हमेशा थाइमिन के साथ जुड़ता है, और साइटोसिन हमेशा ग्वानिन के साथ जुड़ता है। यह कहा जाता है संपूरकता नियम.
संपूरकता नियम:
| ए-टी जी-सी |
उदाहरण के लिए, यदि हमें अनुक्रम के साथ एक डीएनए स्ट्रैंड दिया जाता है
3'- एटीजीटीसीसीटीएजीसीटीजीटीसीजी - 5',
फिर दूसरी श्रृंखला इसकी पूरक होगी और विपरीत दिशा में निर्देशित होगी - 5' सिरे से 3' सिरे तक:
5'- TACAGGATCGACGAGC- 3'.

चावल। 7. डीएनए अणु की श्रृंखलाओं की दिशा और हाइड्रोजन बांड का उपयोग करके नाइट्रोजनस आधारों का कनेक्शन
डी एन ए की नकल
डी एन ए की नकलटेम्पलेट संश्लेषण के माध्यम से डीएनए अणु को दोगुना करने की प्रक्रिया है। प्राकृतिक डीएनए प्रतिकृति के अधिकांश मामलों मेंभजन की पुस्तकडीएनए संश्लेषण के लिए है छोटा टुकड़ा (पुनः निर्मित)। ऐसा राइबोन्यूक्लियोटाइड प्राइमर एंजाइम प्राइमेज़ (प्रोकैरियोट्स में डीएनए प्राइमेज़, यूकेरियोट्स में डीएनए पोलीमरेज़) द्वारा बनाया जाता है, और बाद में इसे डीऑक्सीराइबोन्यूक्लियोटाइड पोलीमरेज़ द्वारा प्रतिस्थापित किया जाता है, जो सामान्य रूप से मरम्मत कार्य करता है (डीएनए अणु में रासायनिक क्षति और टूटने को ठीक करता है)।
प्रतिकृति अर्ध-रूढ़िवादी तंत्र के अनुसार होती है। इसका मतलब यह है कि डीएनए का दोहरा हेलिक्स खुलता है और पूरकता के सिद्धांत के अनुसार इसकी प्रत्येक श्रृंखला पर एक नई श्रृंखला का निर्माण होता है। इस प्रकार बेटी डीएनए अणु में मूल अणु से एक स्ट्रैंड और एक नव संश्लेषित एक स्ट्रैंड होता है। प्रतिकृति मदर स्ट्रैंड के 3' से 5' सिरे तक की दिशा में होती है।

चावल। 8. डीएनए अणु की प्रतिकृति (दोहरीकरण)।
डीएनए संश्लेषण- यह उतनी जटिल प्रक्रिया नहीं है जितनी पहली नज़र में लग सकती है। यदि आप इसके बारे में सोचते हैं, तो सबसे पहले आपको यह पता लगाना होगा कि संश्लेषण क्या है। यह किसी चीज़ को एक संपूर्ण में मिलाने की प्रक्रिया है। एक नए डीएनए अणु का निर्माण कई चरणों में होता है:
1) डीएनए टोपोइज़ोमेरेज़, प्रतिकृति कांटे के सामने स्थित होता है, डीएनए को इसके खुलने और खुलने की सुविधा के लिए काटता है।
2) डीएनए हेलिकेज़, टोपोइज़ोमेरेज़ के बाद, डीएनए हेलिक्स के "अनब्रेडिंग" की प्रक्रिया को प्रभावित करता है।
3) डीएनए-बाध्यकारी प्रोटीन डीएनए स्ट्रैंड को बांधते हैं और उन्हें स्थिर भी करते हैं, जिससे वे एक-दूसरे से चिपकने से बचते हैं।
4) डीएनए पोलीमरेज़ δ(डेल्टा) , प्रतिकृति कांटे की गति की गति के साथ समन्वयित होकर संश्लेषण करता हैअग्रणीचेनसहायक मैट्रिक्स पर 5"→3" दिशा में डीएनएमातृ डीएनए अपने 3" सिरे से 5" सिरे तक की दिशा में घूमता है (प्रति सेकंड 100 न्यूक्लियोटाइड जोड़े तक की गति)। इस पर ये घटनाएँ मातृडीएनए स्ट्रैंड सीमित हैं।

चावल। 9. डीएनए प्रतिकृति प्रक्रिया का योजनाबद्ध प्रतिनिधित्व: (1) लैगिंग स्ट्रैंड (लैगिंग स्ट्रैंड), (2) लीडिंग स्ट्रैंड (अग्रणी स्ट्रैंड), (3) डीएनए पोलीमरेज़ α (पोलα), (4) डीएनए लिगेज, (5) आरएनए -प्राइमर, (6) प्राइमेज़, (7) ओकाज़ाकी टुकड़ा, (8) डीएनए पोलीमरेज़ δ (पोलδ), (9) हेलिकेज़, (10) सिंगल-स्ट्रैंडेड डीएनए-बाइंडिंग प्रोटीन, (11) टोपोइज़ोमेरेज़।
बेटी डीएनए के लैगिंग स्ट्रैंड का संश्लेषण नीचे वर्णित है (देखें)। योजनाप्रतिकृति कांटा और प्रतिकृति एंजाइमों के कार्य)
डीएनए प्रतिकृति के बारे में अधिक जानकारी के लिए देखें
5) मातृ अणु के दूसरे स्ट्रैंड के खुलने और स्थिर होने के तुरंत बाद, यह उससे जुड़ जाता हैडीएनए पोलीमरेज़ α(अल्फा)और 5"→3" दिशा में यह एक प्राइमर (आरएनए प्राइमर) को संश्लेषित करता है - 10 से 200 न्यूक्लियोटाइड की लंबाई के साथ डीएनए टेम्पलेट पर एक आरएनए अनुक्रम। इसके बाद एंजाइमडीएनए स्ट्रैंड से हटा दिया गया।
के बजाय डीएनए पोलीमरेज़α
प्राइमर के 3" सिरे से जुड़ा हुआ हैडीएनए पोलीमरेज़ε
.
6)
डीएनए पोलीमरेज़ε
(एप्सिलॉन) ऐसा लगता है कि प्राइमर का विस्तार जारी है, लेकिन इसे सब्सट्रेट के रूप में सम्मिलित करता हैडीऑक्सीराइबोन्यूक्लियोटाइड्स(150-200 न्यूक्लियोटाइड की मात्रा में)। परिणामस्वरूप, दो भागों से एक एकल धागा बनता है -शाही सेना(यानी प्राइमर) और डीएनए.
डीएनए पोलीमरेज़ εतब तक चलता है जब तक यह पिछले प्राइमर का सामना नहीं कर लेताओकाज़ाकी का टुकड़ा(थोड़ा पहले संश्लेषित)। इसके बाद इस एंजाइम को चेन से हटा दिया जाता है.
7) डीएनए पोलीमरेज़ β(बीटा) इसके स्थान पर खड़ा हैडीएनए पोलीमरेज़ ε,एक ही दिशा (5"→3") में चलता है और प्राइमर राइबोन्यूक्लियोटाइड्स को हटा देता है और साथ ही उनके स्थान पर डीऑक्सीराइबोन्यूक्लियोटाइड्स डालता है। एंजाइम तब तक काम करता है जब तक कि प्राइमर पूरी तरह से हटा न दिया जाए, यानी। जब तक एक डीऑक्सीराइबोन्यूक्लियोटाइड (एक भी पहले संश्लेषित नहीं हो जाताडीएनए पोलीमरेज़ ε). एंजाइम अपने कार्य के परिणाम को सामने वाले डीएनए से जोड़ने में सक्षम नहीं होता है, इसलिए वह श्रृंखला से बाहर हो जाता है।
परिणामस्वरूप, बेटी के डीएनए का एक टुकड़ा माँ के स्ट्रैंड के मैट्रिक्स पर "झूठ" बोलता है। यह कहा जाता हैओकाज़ाकी का टुकड़ा.
8) डीएनए लिगेज दो आसन्न को क्रॉसलिंक करता है ओकाजाकी के टुकड़े , अर्थात। 5" खंड का अंत संश्लेषित किया गयाडीएनए पोलीमरेज़ ε,और 3"-अंत श्रृंखला अंतर्निर्मितडीएनए पोलीमरेज़β .
आरएनए की संरचना
रीबोन्यूक्लीक एसिड(आरएनए) तीन मुख्य मैक्रोमोलेक्यूल्स में से एक है (अन्य दो डीएनए और प्रोटीन हैं) जो सभी जीवित जीवों की कोशिकाओं में पाए जाते हैं।
डीएनए की तरह, आरएनए में एक लंबी श्रृंखला होती है जिसमें प्रत्येक लिंक को बुलाया जाता है न्यूक्लियोटाइड. प्रत्येक न्यूक्लियोटाइड में एक नाइट्रोजनस बेस, एक राइबोस शर्करा और एक फॉस्फेट समूह होता है। हालाँकि, डीएनए के विपरीत, आरएनए में आमतौर पर दो के बजाय एक स्ट्रैंड होता है। आरएनए में पेंटोज़ राइबोज़ है, डीऑक्सीराइबोज़ नहीं (राइबोज़ में दूसरे कार्बोहाइड्रेट परमाणु पर एक अतिरिक्त हाइड्रॉक्सिल समूह होता है)। अंत में, नाइट्रोजनस आधारों की संरचना में डीएनए आरएनए से भिन्न होता है: थाइमिन के बजाय ( टी) आरएनए में यूरैसिल होता है ( यू) , जो एडेनिन का भी पूरक है।
न्यूक्लियोटाइड्स का अनुक्रम आरएनए को आनुवंशिक जानकारी को एनकोड करने की अनुमति देता है। सभी सेलुलर जीव प्रोटीन संश्लेषण को प्रोग्राम करने के लिए आरएनए (एमआरएनए) का उपयोग करते हैं।
सेलुलर आरएनए का उत्पादन नामक प्रक्रिया के माध्यम से किया जाता है TRANSCRIPTION , अर्थात्, डीएनए मैट्रिक्स पर आरएनए का संश्लेषण, विशेष एंजाइमों द्वारा किया जाता है - आरएनए पोलीमरेज़.
मैसेंजर आरएनए (एमआरएनए) तब नामक प्रक्रिया में भाग लेते हैं प्रसारण, वे। राइबोसोम की भागीदारी के साथ एमआरएनए मैट्रिक्स पर प्रोटीन संश्लेषण। अन्य आरएनए प्रतिलेखन के बाद रासायनिक संशोधनों से गुजरते हैं, और माध्यमिक और तृतीयक संरचनाओं के निर्माण के बाद, वे आरएनए के प्रकार के आधार पर कार्य करते हैं।

चावल। 10. नाइट्रोजन बेस में डीएनए और आरएनए के बीच अंतर: आरएनए में थाइमिन (टी) के बजाय यूरैसिल (यू) होता है, जो एडेनिन का पूरक भी है।
TRANSCRIPTION
यह डीएनए टेम्पलेट पर आरएनए संश्लेषण की प्रक्रिया है। डीएनए किसी एक स्थल पर खुलता है। स्ट्रैंड में से एक में ऐसी जानकारी होती है जिसे आरएनए अणु पर कॉपी करने की आवश्यकता होती है - इस स्ट्रैंड को कोडिंग स्ट्रैंड कहा जाता है। डीएनए का दूसरा स्ट्रैंड, कोडिंग वाले का पूरक, टेम्पलेट कहलाता है। प्रतिलेखन के दौरान, एक पूरक आरएनए श्रृंखला को टेम्पलेट स्ट्रैंड पर 3' - 5' दिशा में (डीएनए स्ट्रैंड के साथ) संश्लेषित किया जाता है। यह कोडिंग स्ट्रैंड की एक आरएनए कॉपी बनाता है।
![]()
चावल। 11. प्रतिलेखन का योजनाबद्ध प्रतिनिधित्व
उदाहरण के लिए, यदि हमें कोडिंग श्रृंखला का क्रम दिया गया है
3'- एटीजीटीसीसीटीएजीसीटीजीटीसीजी - 5',
फिर, संपूरकता नियम के अनुसार, मैट्रिक्स श्रृंखला अनुक्रम को आगे बढ़ाएगी
5'- TACAGGATCGACGAGC- 3',
और इससे संश्लेषित आरएनए अनुक्रम है
प्रसारण
आइए तंत्र पर विचार करें प्रोटीन संश्लेषणआरएनए मैट्रिक्स, साथ ही आनुवंशिक कोड और उसके गुणों पर। इसके अलावा, स्पष्टता के लिए, नीचे दिए गए लिंक पर, हम जीवित कोशिका में होने वाली प्रतिलेखन और अनुवाद की प्रक्रियाओं के बारे में एक लघु वीडियो देखने की सलाह देते हैं:

चावल। 12. प्रोटीन संश्लेषण प्रक्रिया: आरएनए के लिए डीएनए कोड, प्रोटीन के लिए आरएनए कोड
जेनेटिक कोड
जेनेटिक कोड- न्यूक्लियोटाइड्स के अनुक्रम का उपयोग करके प्रोटीन के अमीनो एसिड अनुक्रम को एन्कोड करने की एक विधि। प्रत्येक अमीनो एसिड तीन न्यूक्लियोटाइड्स के अनुक्रम द्वारा एन्कोड किया गया है - एक कोडन या ट्रिपलेट।
अधिकांश प्रो- और यूकेरियोट्स के लिए सामान्य आनुवंशिक कोड। तालिका सभी 64 कोडन और संबंधित अमीनो एसिड दिखाती है। आधार क्रम एमआरएनए के 5" से 3" सिरे तक है।
तालिका 1. मानक आनुवंशिक कोड
|
1 tion |
दूसरा आधार |
3 tion |
|||||||
|
यू |
सी |
ए |
जी |
||||||
|
यू |
उ उ उ |
(पीएचई/एफ) |
यू सी यू |
(सेर/एस) |
यू ए यू |
(टायर/वाई) |
यू जी यू |
(सीआईएस/सी) |
यू |
|
उ उ ग |
यू सी सी |
यू ए सी |
यूजीसी |
सी |
|||||
|
उ उ अ |
(लेउ/एल) |
यू सी ए |
यू ए ए |
कोडन बंद करो** |
यू जी ए |
कोडन बंद करो** |
ए |
||
|
उ उ ग |
यू सी जी |
यू ए जी |
कोडन बंद करो** |
यू जी जी |
(टीआरपी/डब्ल्यू) |
जी |
|||
|
सी |
सी यू यू |
सी सी यू |
(प्रो/पी) |
सी ए यू |
(उसका/एच) |
सी जी यू |
(आर्ग/आर) |
यू |
|
|
सी यू सी |
सी सी सी |
सी ए सी |
सी जी सी |
सी |
|||||
|
सी यू ए |
सी सी ए |
सी ए ए |
(जीएलएन/क्यू) |
सी जीए |
ए |
||||
|
सी यू जी |
सी सी जी |
सी ए जी |
सी जी जी |
जी |
|||||
|
ए |
अ उ उ |
(इले/आई) |
ए सी यू |
(थ्र/टी) |
ए ए यू |
(एएसएन/एन) |
ए जी यू |
(सेर/एस) |
यू |
|
ए यू सी |
ए सी सी |
ए ए सी |
ए जी सी |
सी |
|||||
|
ए यू ए |
ए सी ए |
ए ए ए |
(लिस/के) |
ए जी ए |
ए |
||||
|
ए यू जी |
(मुलाकात/एम) |
ए सी जी |
ए ए जी |
ए जी जी |
जी |
||||
|
जी |
जी यू यू |
(वैल/वी) |
जी सी यू |
(अला/ए) |
जी ए यू |
(एएसपी/डी) |
जी जी यू |
(ग्लाइ/जी) |
यू |
|
जी यू सी |
जी सी सी |
जी ए सी |
जी जी सी |
सी |
|||||
|
जी यू ए |
जी सी ए |
जी ए ए |
(गोंद) |
जी जी ए |
ए |
||||
|
जी यू जी |
जी सी जी |
जी ए जी |
जी जी जी |
जी |
|||||
त्रिक के बीच, 4 विशेष क्रम हैं जो "विराम चिह्न" के रूप में कार्य करते हैं:
- *त्रिक अगस्त, एन्कोडिंग मेथिओनिन भी कहा जाता है कोडन प्रारंभ करें. प्रोटीन अणु का संश्लेषण इसी कोडन से शुरू होता है। इस प्रकार, प्रोटीन संश्लेषण के दौरान, अनुक्रम में पहला अमीनो एसिड हमेशा मेथिओनिन होगा।
- ** त्रिक यूएए, यूएजीऔर यू.जी.ए.कहा जाता है कोडन बंद करोऔर एक भी अमीनो एसिड के लिए कोड न करें। इन अनुक्रमों पर, प्रोटीन संश्लेषण रुक जाता है।
आनुवंशिक कोड के गुण
1. त्रिगुण. प्रत्येक अमीनो एसिड तीन न्यूक्लियोटाइड्स के अनुक्रम द्वारा एन्कोड किया गया है - एक ट्रिपलेट या कोडन।
2. निरंतरता. त्रिक के बीच कोई अतिरिक्त न्यूक्लियोटाइड नहीं हैं; जानकारी लगातार पढ़ी जाती है।
3. गैर-अतिव्यापी. एक न्यूक्लियोटाइड को एक ही समय में दो त्रिक में शामिल नहीं किया जा सकता है।
4. असंदिग्धता. एक कोडन केवल एक अमीनो एसिड के लिए कोड कर सकता है।

5. पतनशीलता. एक अमीनो एसिड को कई अलग-अलग कोडन द्वारा एन्कोड किया जा सकता है।

6. बहुमुखी प्रतिभा. आनुवंशिक कोड सभी जीवित जीवों के लिए समान है।
उदाहरण। हमें कोडिंग श्रृंखला का क्रम दिया गया है:
3’- CCGATTGCACGTCGATCGTATA- 5’.
मैट्रिक्स श्रृंखला में अनुक्रम होगा:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
अब हम इस श्रृंखला से सूचना आरएनए को "संश्लेषित" करते हैं:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
प्रोटीन संश्लेषण 5' → 3' दिशा में आगे बढ़ता है, इसलिए, हमें आनुवंशिक कोड को "पढ़ने" के लिए अनुक्रम को उलटने की आवश्यकता है:
5’- AUAUUGCUAGCUGCACGUUAGCC- 3’.
आइए अब प्रारंभ कोडन AUG खोजें:
5’- ए.यू. अगस्त CUAGCUGCACGUUAGCC- 3’.
आइए अनुक्रम को तीन भागों में विभाजित करें:
ऐसा लगता है: जानकारी डीएनए से आरएनए (प्रतिलेखन), आरएनए से प्रोटीन (अनुवाद) में स्थानांतरित की जाती है। डीएनए को प्रतिकृति द्वारा भी दोहराया जा सकता है, और रिवर्स ट्रांसक्रिप्शन की प्रक्रिया भी संभव है, जब डीएनए को आरएनए टेम्पलेट से संश्लेषित किया जाता है, लेकिन यह प्रक्रिया मुख्य रूप से वायरस की विशेषता है।

चावल। 13. आणविक जीव विज्ञान की केंद्रीय हठधर्मिता
जीनोम: जीन और क्रोमोसोम
(सामान्य अवधारणाएँ)
जीनोम - किसी जीव के सभी जीनों की समग्रता; इसका पूरा गुणसूत्र सेट।
शब्द "जीनोम" का प्रस्ताव जी. विंकलर द्वारा 1920 में एक जैविक प्रजाति के जीवों के गुणसूत्रों के अगुणित सेट में निहित जीन के सेट का वर्णन करने के लिए किया गया था। इस शब्द के मूल अर्थ से संकेत मिलता है कि जीनोम की अवधारणा, जीनोटाइप के विपरीत, संपूर्ण प्रजाति की आनुवंशिक विशेषता है, न कि किसी व्यक्ति की। आणविक आनुवंशिकी के विकास के साथ, इस शब्द का अर्थ बदल गया है। यह ज्ञात है कि डीएनए, जो अधिकांश जीवों में आनुवंशिक जानकारी का वाहक है और इसलिए, जीनोम का आधार बनता है, इसमें शब्द के आधुनिक अर्थ में न केवल जीन शामिल हैं। यूकेरियोटिक कोशिकाओं के अधिकांश डीएनए को गैर-कोडिंग ("अनावश्यक") न्यूक्लियोटाइड अनुक्रमों द्वारा दर्शाया जाता है जिसमें प्रोटीन और न्यूक्लिक एसिड के बारे में जानकारी नहीं होती है। इस प्रकार, किसी भी जीव के जीनोम का मुख्य भाग उसके गुणसूत्रों के अगुणित सेट का संपूर्ण डीएनए होता है।
जीन डीएनए अणुओं के खंड हैं जो पॉलीपेप्टाइड्स और आरएनए अणुओं को एनकोड करते हैं
पिछली शताब्दी में, जीन के बारे में हमारी समझ में काफी बदलाव आया है। पहले, जीनोम एक गुणसूत्र का एक क्षेत्र था जो एक विशेषता को एन्कोड या परिभाषित करता था प्ररूपी(दृश्यमान) गुण, जैसे आंखों का रंग।
1940 में, जॉर्ज बीडल और एडवर्ड टैथम ने जीन की आणविक परिभाषा प्रस्तावित की। वैज्ञानिकों ने कवक बीजाणुओं का प्रसंस्करण किया न्यूरोस्पोरा क्रैसाएक्स-रे और अन्य एजेंट जो डीएनए अनुक्रम में परिवर्तन का कारण बनते हैं ( उत्परिवर्तन), और कवक के उत्परिवर्ती उपभेदों की खोज की जिसमें कुछ विशिष्ट एंजाइम खो गए थे, जिसके कारण कुछ मामलों में संपूर्ण चयापचय मार्ग बाधित हो गया। बीडल और टेटम ने निष्कर्ष निकाला कि जीन आनुवंशिक सामग्री का एक टुकड़ा है जो एक एंजाइम के लिए निर्दिष्ट या कोड करता है। इस प्रकार परिकल्पना सामने आई "एक जीन - एक एंजाइम". इस अवधारणा को बाद में परिभाषित करने के लिए विस्तारित किया गया "एक जीन - एक पॉलीपेप्टाइड", क्योंकि कई जीन उन प्रोटीनों को एनकोड करते हैं जो एंजाइम नहीं हैं, और पॉलीपेप्टाइड एक जटिल प्रोटीन कॉम्प्लेक्स की एक सबयूनिट हो सकता है।
चित्र में. चित्र 14 एक आरेख दिखाता है कि कैसे डीएनए में न्यूक्लियोटाइड के त्रिक एक पॉलीपेप्टाइड - एमआरएनए की मध्यस्थता के माध्यम से एक प्रोटीन का अमीनो एसिड अनुक्रम निर्धारित करते हैं। डीएनए श्रृंखलाओं में से एक एमआरएनए के संश्लेषण के लिए एक टेम्पलेट की भूमिका निभाती है, जिसके न्यूक्लियोटाइड ट्रिपलेट्स (कोडन) डीएनए ट्रिपलेट्स के पूरक हैं। कुछ बैक्टीरिया और कई यूकेरियोट्स में, कोडिंग अनुक्रम गैर-कोडिंग क्षेत्रों (जिन्हें कहा जाता है) द्वारा बाधित होते हैं इंट्रोन्स).
जीन का आधुनिक जैव रासायनिक निर्धारण और भी अधिक विशिष्ट. जीन डीएनए के सभी खंड हैं जो अंतिम उत्पादों के प्राथमिक अनुक्रम को एन्कोड करते हैं, जिसमें पॉलीपेप्टाइड्स या आरएनए शामिल होते हैं जिनमें संरचनात्मक या उत्प्रेरक कार्य होता है।
जीन के साथ-साथ, डीएनए में अन्य अनुक्रम भी होते हैं जो विशेष रूप से एक नियामक कार्य करते हैं। नियामक क्रमजीन की शुरुआत या अंत को चिह्नित कर सकता है, प्रतिलेखन को प्रभावित कर सकता है, या प्रतिकृति या पुनर्संयोजन की शुरुआत की साइट को इंगित कर सकता है। कुछ जीनों को अलग-अलग तरीकों से व्यक्त किया जा सकता है, एक ही डीएनए क्षेत्र विभिन्न उत्पादों के निर्माण के लिए एक टेम्पलेट के रूप में कार्य करता है।
हम मोटे तौर पर गणना कर सकते हैं न्यूनतम जीन आकार, मध्य प्रोटीन को एन्कोडिंग करना। पॉलीपेप्टाइड श्रृंखला में प्रत्येक अमीनो एसिड तीन न्यूक्लियोटाइड के अनुक्रम द्वारा एन्कोड किया गया है; इन त्रिक (कोडन) का क्रम पॉलीपेप्टाइड में अमीनो एसिड की श्रृंखला से मेल खाता है जो इस जीन द्वारा एन्कोड किया गया है। 350 अमीनो एसिड अवशेषों (मध्यम लंबाई श्रृंखला) की एक पॉलीपेप्टाइड श्रृंखला 1050 बीपी के अनुक्रम से मेल खाती है। ( बेस जोड़). हालाँकि, कई यूकेरियोटिक जीन और कुछ प्रोकैरियोटिक जीन डीएनए खंडों द्वारा बाधित होते हैं जो प्रोटीन की जानकारी नहीं रखते हैं, और इसलिए एक साधारण गणना से पता चलता है कि वे अधिक लंबे होते हैं।
एक गुणसूत्र पर कितने जीन होते हैं?
 चावल। 15. प्रोकैरियोटिक (बाएं) और यूकेरियोटिक कोशिकाओं में गुणसूत्रों का दृश्य। हिस्टोन परमाणु प्रोटीन का एक बड़ा वर्ग है जो दो मुख्य कार्य करता है: वे नाभिक में डीएनए स्ट्रैंड की पैकेजिंग में और प्रतिलेखन, प्रतिकृति और मरम्मत जैसी परमाणु प्रक्रियाओं के एपिजेनेटिक विनियमन में भाग लेते हैं।
चावल। 15. प्रोकैरियोटिक (बाएं) और यूकेरियोटिक कोशिकाओं में गुणसूत्रों का दृश्य। हिस्टोन परमाणु प्रोटीन का एक बड़ा वर्ग है जो दो मुख्य कार्य करता है: वे नाभिक में डीएनए स्ट्रैंड की पैकेजिंग में और प्रतिलेखन, प्रतिकृति और मरम्मत जैसी परमाणु प्रक्रियाओं के एपिजेनेटिक विनियमन में भाग लेते हैं।
जैसा कि ज्ञात है, जीवाणु कोशिकाओं में एक डीएनए स्ट्रैंड के रूप में एक गुणसूत्र होता है जो एक कॉम्पैक्ट संरचना में व्यवस्थित होता है - एक न्यूक्लियॉइड। प्रोकैरियोटिक गुणसूत्र इशरीकिया कोली, जिसका जीनोम पूरी तरह से समझ लिया गया है, एक गोलाकार डीएनए अणु है (वास्तव में, यह एक पूर्ण चक्र नहीं है, बल्कि शुरुआत या अंत के बिना एक लूप है), जिसमें 4,639,675 बीपी शामिल है। इस अनुक्रम में स्थिर आरएनए अणुओं के लिए लगभग 4,300 प्रोटीन जीन और अन्य 157 जीन शामिल हैं। में मानव जीनोम 24 विभिन्न गुणसूत्रों पर स्थित लगभग 29,000 जीनों के अनुरूप लगभग 3.1 अरब आधार जोड़े।
प्रोकैरियोट्स (बैक्टीरिया)।
 जीवाणु ई कोलाईइसमें एक डबल-स्ट्रैंडेड गोलाकार डीएनए अणु है। इसमें 4,639,675 बीपी शामिल है। और लगभग 1.7 मिमी की लंबाई तक पहुंचता है, जो कोशिका की लंबाई से अधिक है ई कोलाईलगभग 850 बार. न्यूक्लियॉइड के हिस्से के रूप में बड़े गोलाकार गुणसूत्र के अलावा, कई बैक्टीरिया में एक या कई छोटे गोलाकार डीएनए अणु होते हैं जो साइटोसोल में स्वतंत्र रूप से स्थित होते हैं। ये एक्स्ट्राक्रोमोसोमल तत्व कहलाते हैं प्लाज्मिड्स(चित्र 16)।
जीवाणु ई कोलाईइसमें एक डबल-स्ट्रैंडेड गोलाकार डीएनए अणु है। इसमें 4,639,675 बीपी शामिल है। और लगभग 1.7 मिमी की लंबाई तक पहुंचता है, जो कोशिका की लंबाई से अधिक है ई कोलाईलगभग 850 बार. न्यूक्लियॉइड के हिस्से के रूप में बड़े गोलाकार गुणसूत्र के अलावा, कई बैक्टीरिया में एक या कई छोटे गोलाकार डीएनए अणु होते हैं जो साइटोसोल में स्वतंत्र रूप से स्थित होते हैं। ये एक्स्ट्राक्रोमोसोमल तत्व कहलाते हैं प्लाज्मिड्स(चित्र 16)।
अधिकांश प्लास्मिड में केवल कुछ हजार बेस जोड़े होते हैं, कुछ में 10,000 बीपी से अधिक होते हैं। वे आनुवांशिक जानकारी रखते हैं और बेटी प्लास्मिड बनाने के लिए प्रतिकृति बनाते हैं, जो मूल कोशिका के विभाजन के दौरान बेटी कोशिकाओं में प्रवेश करते हैं। प्लास्मिड न केवल बैक्टीरिया में, बल्कि यीस्ट और अन्य कवक में भी पाए जाते हैं। कई मामलों में, प्लास्मिड मेजबान कोशिकाओं को कोई लाभ नहीं पहुंचाते हैं और उनका एकमात्र उद्देश्य स्वतंत्र रूप से प्रजनन करना है। हालाँकि, कुछ प्लास्मिड मेजबान के लिए लाभकारी जीन ले जाते हैं। उदाहरण के लिए, प्लास्मिड में मौजूद जीन जीवाणु कोशिकाओं को जीवाणुरोधी एजेंटों के प्रति प्रतिरोधी बना सकते हैं। β-लैक्टामेज़ जीन वाले प्लास्मिड पेनिसिलिन और एमोक्सिसिलिन जैसे β-लैक्टम एंटीबायोटिक दवाओं के प्रति प्रतिरोध प्रदान करते हैं। प्लास्मिड उन कोशिकाओं से पारित हो सकते हैं जो एंटीबायोटिक दवाओं के प्रति प्रतिरोधी हैं, उसी या बैक्टीरिया की एक अलग प्रजाति की अन्य कोशिकाओं में, जिससे वे कोशिकाएं भी प्रतिरोधी बन जाती हैं। एंटीबायोटिक दवाओं का गहन उपयोग एक शक्तिशाली चयनात्मक कारक है जो रोगजनक बैक्टीरिया के बीच एंटीबायोटिक प्रतिरोध को एन्कोड करने वाले प्लास्मिड (साथ ही समान जीन को एन्कोड करने वाले ट्रांसपोज़न) के प्रसार को बढ़ावा देता है, जिससे कई एंटीबायोटिक दवाओं के प्रतिरोध के साथ बैक्टीरिया के उपभेदों का उद्भव होता है। डॉक्टर एंटीबायोटिक दवाओं के व्यापक उपयोग के खतरों को समझने लगे हैं और केवल तत्काल आवश्यकता के मामलों में ही उन्हें लिखते हैं। समान कारणों से, खेत जानवरों के इलाज के लिए एंटीबायोटिक दवाओं का व्यापक उपयोग सीमित है।
यह सभी देखें: रविन एन.वी., शेस्ताकोव एस.वी. प्रोकैरियोट्स का जीनोम // वेविलोव जर्नल ऑफ जेनेटिक्स एंड ब्रीडिंग, 2013. टी. 17. नंबर 4/2। पृ. 972-984.
यूकेरियोट्स।
तालिका 2. कुछ जीवों के डीएनए, जीन और गुणसूत्र
|
साझा डीएनए पी.एन. |
गुणसूत्रों की संख्या* |
जीन की अनुमानित संख्या |
|
|
इशरीकिया कोली(जीवाणु) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(यीस्ट) |
12 080 000 |
16** |
5 860 |
|
काईऩोर्हेब्डीटीज एलिगेंस(नेमाटोड) |
90 269 800 |
12*** |
23 000 |
|
अरबीडोफिसिस थालीआना(पौधा) |
119 186 200 |
33 000 |
|
|
ड्रोसोफिला मेलानोगास्टर(फल का कीड़ा) |
120 367 260 |
20 000 |
|
|
ओरिजा सैटिवा(चावल) |
480 000 000 |
57 000 |
|
|
घरेलू चूहा(चूहा) |
2 634 266 500 |
27 000 |
|
|
होमो सेपियन्स(इंसान) |
3 070 128 600 |
29 000 |
टिप्पणी।जानकारी लगातार अद्यतन की जाती है; अधिक नवीनतम जानकारी के लिए, व्यक्तिगत जीनोमिक्स परियोजना वेबसाइटें देखें
* यीस्ट को छोड़कर सभी यूकेरियोट्स के लिए, गुणसूत्रों का द्विगुणित सेट दिया गया है। द्विगुणितकिट गुणसूत्र (ग्रीक डिप्लूज़ से - डबल और ईडोस - प्रजाति) - गुणसूत्रों का एक दोहरा सेट (2n), जिनमें से प्रत्येक में एक समजात होता है।
**अगुणित सेट. जंगली खमीर उपभेदों में आम तौर पर इन गुणसूत्रों के आठ (ऑक्टाप्लोइड) या अधिक सेट होते हैं।
***दो एक्स गुणसूत्र वाली महिलाओं के लिए। पुरुषों में X गुणसूत्र होता है, लेकिन Y नहीं, यानी केवल 11 गुणसूत्र होते हैं।
सबसे छोटे यूकेरियोट्स में से एक, यीस्ट में 2.6 गुना अधिक डीएनए होता है ई कोलाई(तालिका 2)। फल मक्खी कोशिकाएँ ड्रोसोफिलाआनुवंशिक अनुसंधान का एक क्लासिक विषय, इसमें 35 गुना अधिक डीएनए होता है, और मानव कोशिकाओं में लगभग 700 गुना अधिक डीएनए होता है ई कोलाई।कई पौधों और उभयचरों में और भी अधिक डीएनए होता है। यूकेरियोटिक कोशिकाओं की आनुवंशिक सामग्री गुणसूत्रों के रूप में व्यवस्थित होती है। गुणसूत्रों का द्विगुणित सेट (2 एन) जीव के प्रकार पर निर्भर करता है (तालिका 2)।
उदाहरण के लिए, मानव दैहिक कोशिका में 46 गुणसूत्र होते हैं ( चावल। 17). यूकेरियोटिक कोशिका का प्रत्येक गुणसूत्र, जैसा कि चित्र में दिखाया गया है। 17, ए, में एक बहुत बड़ा डबल-स्ट्रैंडेड डीएनए अणु होता है। चौबीस मानव गुणसूत्र (22 युग्मित गुणसूत्र और दो लिंग गुणसूत्र X और Y) की लंबाई 25 गुना से अधिक भिन्न होती है। प्रत्येक यूकेरियोटिक गुणसूत्र में जीन का एक विशिष्ट सेट होता है।

चावल। 17. यूकेरियोट्स के गुणसूत्र।ए- मानव गुणसूत्र से जुड़े और संघनित बहन क्रोमैटिड की एक जोड़ी। इस रूप में, यूकेरियोटिक गुणसूत्र प्रतिकृति के बाद और माइटोसिस के दौरान मेटाफ़ेज़ में रहते हैं। बी- पुस्तक के लेखकों में से एक के ल्यूकोसाइट से गुणसूत्रों का एक पूरा सेट। प्रत्येक सामान्य मानव दैहिक कोशिका में 46 गुणसूत्र होते हैं।
यदि आप मानव जीनोम (22 गुणसूत्र और गुणसूत्र X और Y या X और X) के डीएनए अणुओं को जोड़ते हैं, तो आपको लगभग एक मीटर लंबा अनुक्रम मिलता है। ध्यान दें: सभी स्तनधारियों और अन्य विषमलैंगिक नर जीवों में, मादाओं में दो X गुणसूत्र (XX) होते हैं और पुरुषों में एक X गुणसूत्र और एक Y गुणसूत्र (XY) होता है।
अधिकांश मानव कोशिकाएँ, इसलिए ऐसी कोशिकाओं की कुल डीएनए लंबाई लगभग 2 मीटर होती है। एक वयस्क मनुष्य में लगभग 10 14 कोशिकाएँ होती हैं, इसलिए सभी डीएनए अणुओं की कुल लंबाई 2・10 11 किमी होती है। तुलना के लिए, पृथ्वी की परिधि 4・10 4 किमी है, और पृथ्वी से सूर्य की दूरी 1.5・10 8 किमी है। इस प्रकार हमारी कोशिकाओं में आश्चर्यजनक रूप से सघन डीएनए भरा हुआ है!
यूकेरियोटिक कोशिकाओं में डीएनए युक्त अन्य अंग होते हैं - माइटोकॉन्ड्रिया और क्लोरोप्लास्ट। माइटोकॉन्ड्रियल और क्लोरोप्लास्ट डीएनए की उत्पत्ति के संबंध में कई परिकल्पनाएं सामने रखी गई हैं। आज आम तौर पर स्वीकृत दृष्टिकोण यह है कि वे प्राचीन बैक्टीरिया के गुणसूत्रों के मूल तत्वों का प्रतिनिधित्व करते हैं, जो मेजबान कोशिकाओं के साइटोप्लाज्म में प्रवेश करते हैं और इन ऑर्गेनेल के अग्रदूत बन जाते हैं। माइटोकॉन्ड्रियल डीएनए माइटोकॉन्ड्रियल टीआरएनए और आरआरएनए, साथ ही कई माइटोकॉन्ड्रियल प्रोटीन को एनकोड करता है। 95% से अधिक माइटोकॉन्ड्रियल प्रोटीन परमाणु डीएनए द्वारा एन्कोड किए गए हैं।
जीन की संरचना
आइए प्रोकैरियोट्स और यूकेरियोट्स में जीन की संरचना, उनकी समानताएं और अंतर पर विचार करें। इस तथ्य के बावजूद कि जीन डीएनए का एक खंड है जो केवल एक प्रोटीन या आरएनए को एनकोड करता है, तत्काल कोडिंग भाग के अलावा, इसमें नियामक और अन्य संरचनात्मक तत्व भी शामिल होते हैं जिनकी प्रोकैरियोट्स और यूकेरियोट्स में अलग-अलग संरचनाएं होती हैं।
कोडिंग क्रम- जीन की मुख्य संरचनात्मक और कार्यात्मक इकाई, इसमें न्यूक्लियोटाइड एन्कोडिंग के त्रिक स्थित होते हैंअमीनो एसिड अनुक्रम. यह एक प्रारंभ कोडन से शुरू होता है और एक स्टॉप कोडन के साथ समाप्त होता है।
कोडिंग अनुक्रम से पहले और बाद में हैं अअनुवादित 5' और 3' अनुक्रम. वे विनियामक और सहायक कार्य करते हैं, उदाहरण के लिए, एमआरएनए पर राइबोसोम की लैंडिंग सुनिश्चित करना।
अअनुवादित और कोडिंग अनुक्रम प्रतिलेखन इकाई बनाते हैं - डीएनए का प्रतिलेखित खंड, यानी डीएनए का वह भाग जहां से एमआरएनए संश्लेषण होता है।
टर्मिनेटर- जीन के अंत में डीएनए का एक गैर-प्रतिलेखित खंड जहां आरएनए संश्लेषण बंद हो जाता है।
जीन की शुरुआत में है नियामक क्षेत्र, जो भी शामिल है प्रमोटरऔर ऑपरेटर.
प्रमोटर- वह क्रम जिससे पोलीमरेज़ प्रतिलेखन आरंभ के दौरान बंधता है। ऑपरेटर- यह एक ऐसा क्षेत्र है जिससे विशेष प्रोटीन बंध सकते हैं - दमनकारी, जो इस जीन से आरएनए संश्लेषण की गतिविधि को कम कर सकता है - दूसरे शब्दों में, इसे कम करें अभिव्यक्ति.
प्रोकैरियोट्स में जीन संरचना
प्रोकैरियोट्स और यूकेरियोट्स में जीन संरचना की सामान्य योजना अलग नहीं है - दोनों में एक प्रमोटर और ऑपरेटर के साथ एक नियामक क्षेत्र, कोडिंग और अअनुवादित अनुक्रमों के साथ एक प्रतिलेखन इकाई और एक टर्मिनेटर होता है। हालाँकि, प्रोकैरियोट्स और यूकेरियोट्स में जीन का संगठन अलग है।

चावल। 18. प्रोकैरियोट्स (बैक्टीरिया) में जीन संरचना की योजना -छवि बड़ी हो गई है
ऑपेरॉन की शुरुआत और अंत में कई संरचनात्मक जीनों के लिए सामान्य नियामक क्षेत्र होते हैं। ऑपेरॉन के लिखित क्षेत्र से, एक एमआरएनए अणु पढ़ा जाता है, जिसमें कई कोडिंग अनुक्रम होते हैं, जिनमें से प्रत्येक का अपना प्रारंभ और स्टॉप कोडन होता है। इनमें से प्रत्येक क्षेत्र सेएक प्रोटीन संश्लेषित होता है। इस प्रकार, एक एमआरएनए अणु से कई प्रोटीन अणुओं का संश्लेषण होता है।
प्रोकैरियोट्स को एक ही कार्यात्मक इकाई में कई जीनों के संयोजन की विशेषता है - ओपेरोन. ऑपेरॉन के संचालन को अन्य जीनों द्वारा नियंत्रित किया जा सकता है, जो ऑपेरॉन से काफ़ी दूर हो सकते हैं - नियामक. इस जीन से अनुवादित प्रोटीन को कहा जाता है दमनकारी. यह ऑपेरॉन के संचालक से जुड़ जाता है और इसमें मौजूद सभी जीनों की अभिव्यक्ति को एक साथ नियंत्रित करता है।
प्रोकैरियोट्स की विशेषता भी इस घटना से होती है प्रतिलेखन-अनुवाद इंटरफ़ेस.
![]()
चावल। 19 प्रोकैरियोट्स में प्रतिलेखन और अनुवाद के युग्मन की घटना - छवि बड़ी हो गई है
यूकेरियोट्स में ऐसा युग्मन एक परमाणु आवरण की उपस्थिति के कारण नहीं होता है जो साइटोप्लाज्म को, जहां अनुवाद होता है, उस आनुवंशिक सामग्री से अलग करता है जिस पर प्रतिलेखन होता है। प्रोकैरियोट्स में, डीएनए टेम्पलेट पर आरएनए संश्लेषण के दौरान, एक राइबोसोम तुरंत संश्लेषित आरएनए अणु से जुड़ सकता है। इस प्रकार, प्रतिलेखन पूरा होने से पहले ही अनुवाद शुरू हो जाता है। इसके अलावा, कई राइबोसोम एक साथ एक आरएनए अणु से जुड़ सकते हैं, एक ही प्रोटीन के कई अणुओं को एक साथ संश्लेषित कर सकते हैं।
यूकेरियोट्स में जीन संरचना
यूकेरियोट्स के जीन और गुणसूत्र बहुत जटिल रूप से व्यवस्थित होते हैं
बैक्टीरिया की कई प्रजातियों में केवल एक गुणसूत्र होता है, और लगभग सभी मामलों में प्रत्येक गुणसूत्र पर प्रत्येक जीन की एक प्रति होती है। केवल कुछ जीन, जैसे कि आरआरएनए जीन, कई प्रतियों में पाए जाते हैं। जीन और नियामक अनुक्रम वस्तुतः संपूर्ण प्रोकैरियोटिक जीनोम बनाते हैं। इसके अलावा, लगभग हर जीन सख्ती से अमीनो एसिड अनुक्रम (या आरएनए अनुक्रम) से मेल खाता है जिसे वह एन्कोड करता है (चित्र 14)।
यूकेरियोटिक जीन का संरचनात्मक और कार्यात्मक संगठन बहुत अधिक जटिल है। यूकेरियोटिक गुणसूत्रों का अध्ययन, और बाद में संपूर्ण यूकेरियोटिक जीनोम अनुक्रमों का अनुक्रमण, कई आश्चर्य लेकर आया। कई, यदि अधिकांश नहीं, तो यूकेरियोटिक जीन में एक दिलचस्प विशेषता होती है: उनके न्यूक्लियोटाइड अनुक्रमों में एक या अधिक डीएनए अनुभाग होते हैं जो पॉलीपेप्टाइड उत्पाद के अमीनो एसिड अनुक्रम को एन्कोड नहीं करते हैं। इस तरह के अअनुवादित सम्मिलन जीन के न्यूक्लियोटाइड अनुक्रम और एन्कोडेड पॉलीपेप्टाइड के अमीनो एसिड अनुक्रम के बीच सीधे पत्राचार को बाधित करते हैं। जीन के भीतर इन अअनुवादित खंडों को कहा जाता है इंट्रोन्स, या निर्मित में दृश्यों, और कोडिंग खंड हैं एक्सॉनों. प्रोकैरियोट्स में, केवल कुछ जीनों में इंट्रॉन होते हैं।
तो, यूकेरियोट्स में, जीन का ऑपेरॉन में संयोजन व्यावहारिक रूप से नहीं होता है, और यूकेरियोटिक जीन का कोडिंग अनुक्रम अक्सर अनुवादित क्षेत्रों में विभाजित होता है - एक्सॉन, और अअनुवादित अनुभाग - introns.
ज्यादातर मामलों में, इंट्रोन्स का कार्य स्थापित नहीं होता है। सामान्य तौर पर, मानव डीएनए का केवल 1.5% ही "कोडिंग" होता है, यानी यह प्रोटीन या आरएनए के बारे में जानकारी रखता है। हालाँकि, बड़े इंट्रोन्स को ध्यान में रखते हुए, यह पता चलता है कि मानव डीएनए 30% जीन है। क्योंकि जीन मानव जीनोम का अपेक्षाकृत छोटा हिस्सा बनाते हैं, डीएनए का एक महत्वपूर्ण हिस्सा अज्ञात रहता है।

चावल। 16. यूकेरियोट्स में जीन संरचना की योजना - छवि बड़ी हो गई है
प्रत्येक जीन से, पहले अपरिपक्व या प्री-आरएनए को संश्लेषित किया जाता है, जिसमें इंट्रॉन और एक्सॉन दोनों होते हैं।
इसके बाद, स्प्लिसिंग प्रक्रिया होती है, जिसके परिणामस्वरूप पुराने क्षेत्रों को एक्साइज किया जाता है, और एक परिपक्व एमआरएनए बनता है, जिससे प्रोटीन को संश्लेषित किया जा सकता है।

चावल। 20. वैकल्पिक स्प्लिसिंग प्रक्रिया - छवि बड़ी हो गई है
उदाहरण के लिए, जीन का यह संगठन अनुमति देता है, जब प्रोटीन के विभिन्न रूपों को एक जीन से संश्लेषित किया जा सकता है, इस तथ्य के कारण कि स्प्लिसिंग के दौरान एक्सॉन को विभिन्न अनुक्रमों में एक साथ जोड़ा जा सकता है।

चावल। 21. प्रोकैरियोट्स और यूकेरियोट्स के जीन की संरचना में अंतर - छवि बड़ी हो गई है
उत्परिवर्तन और उत्परिवर्तन
उत्परिवर्तनजीनोटाइप में लगातार परिवर्तन को कहा जाता है, अर्थात न्यूक्लियोटाइड अनुक्रम में परिवर्तन।
वह प्रक्रिया जो उत्परिवर्तन की ओर ले जाती है, कहलाती है म्युटाजेनेसिस, और शरीर सभीजिनकी कोशिकाओं में समान उत्परिवर्तन होता है - उत्परिवर्ती.
उत्परिवर्तन सिद्धांतपहली बार 1903 में ह्यूगो डी व्रीज़ द्वारा तैयार किया गया था। इसके आधुनिक संस्करण में निम्नलिखित प्रावधान शामिल हैं:
1. उत्परिवर्तन अचानक, आक्षेपिक रूप से घटित होते हैं।
2. उत्परिवर्तन पीढ़ी-दर-पीढ़ी हस्तांतरित होते रहते हैं।
3. उत्परिवर्तन लाभकारी, हानिकारक या तटस्थ, प्रभावी या अप्रभावी हो सकते हैं।
4. उत्परिवर्तन का पता लगाने की संभावना अध्ययन किए गए व्यक्तियों की संख्या पर निर्भर करती है।
5. समान उत्परिवर्तन बार-बार हो सकते हैं।
6. उत्परिवर्तन निर्देशित नहीं होते.
उत्परिवर्तन विभिन्न कारकों के प्रभाव में हो सकते हैं। ऐसे उत्परिवर्तन होते हैं जो इसके प्रभाव में उत्पन्न होते हैं उत्परिवर्ती प्रभाव डालता है: भौतिक (उदाहरण के लिए, पराबैंगनी या विकिरण), रासायनिक (उदाहरण के लिए, कोल्सीसीन या प्रतिक्रियाशील ऑक्सीजन प्रजातियां) और जैविक (उदाहरण के लिए, वायरस)। उत्परिवर्तन भी उत्पन्न हो सकते हैं प्रतिकृति त्रुटियाँ.
उन स्थितियों के आधार पर जिनके तहत उत्परिवर्तन प्रकट होते हैं, उत्परिवर्तन को विभाजित किया जाता है अविरल- यानी, उत्परिवर्तन जो सामान्य परिस्थितियों में उत्पन्न हुए, और प्रेरित किया- अर्थात्, उत्परिवर्तन जो विशेष परिस्थितियों में उत्पन्न हुए।
उत्परिवर्तन न केवल परमाणु डीएनए में हो सकते हैं, बल्कि उदाहरण के लिए, माइटोकॉन्ड्रियल या प्लास्टिड डीएनए में भी हो सकते हैं। तदनुसार, हम भेद कर सकते हैं नाभिकीयऔर साइटोप्लाज्मिकउत्परिवर्तन.
उत्परिवर्तन के परिणामस्वरूप, नए एलील अक्सर प्रकट हो सकते हैं। यदि एक उत्परिवर्ती एलील सामान्य एलील की क्रिया को दबा देता है, तो उत्परिवर्तन कहा जाता है प्रमुख. यदि एक सामान्य एलील किसी उत्परिवर्ती को दबा देता है, तो इस उत्परिवर्तन को कहा जाता है पीछे हटने का. अधिकांश उत्परिवर्तन जो नए एलील्स के उद्भव की ओर ले जाते हैं, अप्रभावी होते हैं।
उत्परिवर्तन प्रभाव से भिन्न होते हैं अनुकूलीजिससे पर्यावरण के प्रति जीव की अनुकूलनशीलता बढ़ जाती है, तटस्थ, जो अस्तित्व को प्रभावित नहीं करता, हानिकारक, पर्यावरणीय परिस्थितियों के प्रति जीवों की अनुकूलनशीलता को कम करना और घातक, जिससे विकास के प्रारंभिक चरण में ही जीव की मृत्यु हो जाती है।
परिणामों के अनुसार, उत्परिवर्तन के कारण प्रोटीन कार्य का नुकसान, उत्परिवर्तन की ओर ले जाता है उद्भव प्रोटीन का एक नया कार्य है, साथ ही साथ उत्परिवर्तन भी जीन खुराक बदलें, और, तदनुसार, इससे संश्लेषित प्रोटीन की खुराक।
उत्परिवर्तन शरीर की किसी भी कोशिका में हो सकता है। यदि किसी रोगाणु कोशिका में उत्परिवर्तन होता है, तो इसे कहा जाता है जीवाणु-संबंधी(जर्मिनल या जनरेटिव)। इस तरह के उत्परिवर्तन उस जीव में प्रकट नहीं होते हैं जिसमें वे दिखाई देते हैं, बल्कि संतानों में उत्परिवर्ती की उपस्थिति का कारण बनते हैं और विरासत में मिलते हैं, इसलिए वे आनुवंशिकी और विकास के लिए महत्वपूर्ण हैं। यदि किसी अन्य कोशिका में उत्परिवर्तन होता है, तो इसे कहा जाता है दैहिक. इस तरह का उत्परिवर्तन किसी न किसी हद तक उस जीव में प्रकट हो सकता है जिसमें यह उत्पन्न हुआ है, उदाहरण के लिए, कैंसर के ट्यूमर के गठन का कारण बनता है। हालाँकि, ऐसा उत्परिवर्तन विरासत में नहीं मिलता है और वंशजों को प्रभावित नहीं करता है।
उत्परिवर्तन विभिन्न आकार के जीनोम के क्षेत्रों को प्रभावित कर सकते हैं। प्रमुखता से दिखाना आनुवंशिक, गुणसूत्रऔर जीनोमिकउत्परिवर्तन.
जीन उत्परिवर्तन
एक जीन से छोटे पैमाने पर होने वाले उत्परिवर्तन कहलाते हैं आनुवंशिक, या बिंदु (बिंदु). इस तरह के उत्परिवर्तन से अनुक्रम में एक या कई न्यूक्लियोटाइड में परिवर्तन होता है। जीन उत्परिवर्तनों में से हैंप्रतिस्थापन, जिससे एक न्यूक्लियोटाइड का प्रतिस्थापन दूसरे न्यूक्लियोटाइड से हो जाता है,हटाए, जिससे न्यूक्लियोटाइड में से एक का नुकसान हो जाता है,निवेशन, जिससे अनुक्रम में एक अतिरिक्त न्यूक्लियोटाइड जुड़ गया।

चावल। 23. जीन (बिंदु) उत्परिवर्तन
प्रोटीन पर क्रिया के तंत्र के अनुसार, जीन उत्परिवर्तन को इसमें विभाजित किया गया है:पर्याय, जो (आनुवंशिक कोड की विकृति के परिणामस्वरूप) प्रोटीन उत्पाद की अमीनो एसिड संरचना में परिवर्तन नहीं करता है,गलत उत्परिवर्तन, जो एक अमीनो एसिड को दूसरे के साथ प्रतिस्थापित कर देता है और संश्लेषित प्रोटीन की संरचना को प्रभावित कर सकता है, हालांकि वे अक्सर महत्वहीन होते हैं,बकवास उत्परिवर्तन, जिससे कोडिंग कोडन को स्टॉप कोडन से प्रतिस्थापित किया जा सके,उत्परिवर्तन की ओर ले जाता है स्प्लिसिंग विकार:

चावल। 24. उत्परिवर्तन पैटर्न
इसके अलावा, प्रोटीन पर कार्रवाई के तंत्र के अनुसार, उत्परिवर्तन को प्रतिष्ठित किया जाता है फ्रेम शिफ्ट पढ़ना, जैसे सम्मिलन और विलोपन। निरर्थक उत्परिवर्तन जैसे ऐसे उत्परिवर्तन, हालांकि वे जीन में एक बिंदु पर होते हैं, अक्सर प्रोटीन की पूरी संरचना को प्रभावित करते हैं, जिससे इसकी संरचना में पूर्ण परिवर्तन हो सकता है।
चावल। 29. दोहराव से पहले और बाद में गुणसूत्र
जीनोमिक उत्परिवर्तन
अंत में, जीनोमिक उत्परिवर्तनपूरे जीनोम को प्रभावित करते हैं, यानी गुणसूत्रों की संख्या बदल जाती है। पॉलीप्लोइडीज़ हैं - कोशिका की प्लोइडी में वृद्धि, और एन्यूप्लोइडीज़, यानी, गुणसूत्रों की संख्या में परिवर्तन, उदाहरण के लिए, ट्राइसॉमी (गुणसूत्रों में से एक पर एक अतिरिक्त समरूपता की उपस्थिति) और मोनोसॉमी (की अनुपस्थिति) एक गुणसूत्र पर एक समरूपता)।
डीएनए पर वीडियो
डीएनए प्रतिकृति, आरएनए कोडिंग, प्रोटीन संश्लेषण
डीएनए(डीऑक्सीराइबोन्यूक्लिक एसिड) एक जैविक बहुलक है जिसमें दो पॉलीन्यूक्लियोटाइड श्रृंखलाएं एक दूसरे से जुड़ी होती हैं। डीएनए श्रृंखला में से प्रत्येक को बनाने वाले मोनोमर्स जटिल कार्बनिक यौगिक होते हैं जिनमें चार नाइट्रोजनस आधारों में से एक शामिल होता है: एडेनिन (ए) या थाइमिन (टी), साइटोसिन (सी) या गुआनिन (जी), पांच-परमाणु चीनी पेंटोस - डीऑक्सीराइबोज , जिसका नाम डीएनए के नाम के साथ-साथ फॉस्फोरिक एसिड अवशेष के नाम पर रखा गया है। इन यौगिकों को न्यूक्लियोटाइड्स कहा जाता है।
ये शृंखलाएं पूरकता के सिद्धांत के अनुसार अपने नाइट्रोजनी आधारों के बीच हाइड्रोजन बांड द्वारा एक दूसरे से जुड़ी हुई हैं। एक श्रृंखला का एडेनिन दो हाइड्रोजन बंधों द्वारा दूसरी श्रृंखला के थाइमिन से जुड़ा होता है, और विभिन्न श्रृंखलाओं के गुआनिन और साइटोसिन के बीच तीन हाइड्रोजन बंध बनते हैं। नाइट्रोजनस आधारों का यह कनेक्शन दो श्रृंखलाओं के बीच एक मजबूत संबंध सुनिश्चित करता है और उनके बीच समान दूरी बनाए रखता है।
एक डीएनए अणु में दो पॉलीन्यूक्लियोटाइड श्रृंखलाओं के संयोजन की एक अन्य महत्वपूर्ण विशेषता उनकी प्रतिसमानांतरता है: एक श्रृंखला का 5" सिरा दूसरे के 3" सिरे से जुड़ा होता है, और इसके विपरीत।
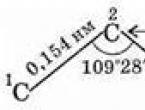
डीएनए अणु, COMP. दो श्रृंखलाओं से, यह अपनी धुरी के चारों ओर मुड़ा हुआ एक सर्पिल बनाता है। हेलिक्स व्यास 2 एनएम है, पिच की लंबाई 3.4 एनएम है। प्रत्येक मोड़ में 10 जोड़े न्यूक्लियोटाइड होते हैं।
* अधिकतर, डबल हेलिकॉप्टर दाहिने हाथ के होते हैं। समाधान में अधिकांश डीएनए अणु दाहिने हाथ में होते हैं - बी-फॉर्म (बी-डीएनए)। हालाँकि, बाएं हाथ के रूप (जेड-डीएनए) भी होते हैं। यह डीएनए कोशिकाओं में कितना मौजूद है और इसका जैविक महत्व क्या है, यह अभी तक स्थापित नहीं हुआ है।
* इस प्रकार, हम डीएनए अणु के संरचनात्मक संगठन में अंतर कर सकते हैं प्राथमिक संरचना - पॉलीन्यूक्लियोटाइड श्रृंखला, द्वितीयक संरचना- हाइड्रोजन बांड से जुड़ी दो पूरक और एंटीपैरेलल पॉलीन्यूक्लियोटाइड श्रृंखलाएं, और तृतीयक संरचना - उपरोक्त स्थानिक विशेषताओं के साथ एक त्रि-आयामी सर्पिल।
9. कोशिका में RNA के प्रकार। विभिन्न आरएनए के कार्य
एक मध्यस्थ की भूमिका, जिसका कार्य डीएनए में संग्रहीत वंशानुगत जानकारी को कार्यशील रूप में अनुवाद करना है, द्वारा निभाई जाती है राइबोन्यूक्लिक एसिड - आरएनए.
दो- और एक-फंसे आरएनए अणु ज्ञात हैं। डबल-स्ट्रैंडेड आरएनए कुछ वायरस में वंशानुगत जानकारी को संग्रहीत और पुन: पेश करने का कार्य करता है, अर्थात। वे गुणसूत्रों का कार्य करते हैं। एकल-फंसे आरएनए प्रोटीन में अमीनो एसिड के अनुक्रम के बारे में जानकारी गुणसूत्र से उनके संश्लेषण के स्थान तक ले जाते हैं और संश्लेषण प्रक्रियाओं में भाग लेते हैं।
डीएनए अणुओं के विपरीत, राइबोन्यूक्लिक एसिड को एक एकल पॉलीन्यूक्लियोटाइड श्रृंखला द्वारा दर्शाया जाता है, जिसमें चार प्रकार के न्यूक्लियोटाइड होते हैं जिनमें चीनी, राइबोस, फॉस्फेट और चार नाइट्रोजनस आधारों में से एक होता है - एडेनिन, गुआनिन, यूरैसिल या साइटोसिन। आरएनए को पूरकता और एंटीपैरेललिज्म के सिद्धांत के अनुपालन में आरएनए पोलीमरेज़ एंजाइमों का उपयोग करके डीएनए अणुओं पर संश्लेषित किया जाता है, और यूरैसिल आरएनए में डीएनए एडेनिन का पूरक है। कोशिका में सक्रिय आरएनए की संपूर्ण विविधता को तीन मुख्य प्रकारों में विभाजित किया जा सकता है: एमआरएनए, टीआरएनए, आरआरएनए।
मैट्रिक्स, या सूचना, आरएनए (एमआरएनए, या एमआरएनए)। प्रतिलेखन।निर्दिष्ट गुणों वाले प्रोटीन को संश्लेषित करने के लिए, पेप्टाइड श्रृंखला में अमीनो एसिड को शामिल करने के क्रम के बारे में उनके निर्माण के स्थान पर "निर्देश" भेजे जाते हैं। यह निर्देश न्यूक्लियोटाइड अनुक्रम में निहित है आव्यूह,या संदेशवाहक आरएनए(एमआरएनए, एमआरएनए) डीएनए के संबंधित वर्गों में संश्लेषित होता है। mRNA संश्लेषण की प्रक्रिया कहलाती है प्रतिलेखन।
एमआरएनए का संश्लेषण आरएनए पोलीमरेज़ द्वारा डीएनए अणु में एक विशेष क्षेत्र की खोज से शुरू होता है, जो उस स्थान को इंगित करता है जहां प्रतिलेखन शुरू होता है - प्रमोटरप्रमोटर से बंधने के बाद, आरएनए पोलीमरेज़ डीएनए हेलिक्स के आसन्न मोड़ को खोल देता है। इस बिंदु पर दो डीएनए स्ट्रैंड अलग हो जाते हैं, और उनमें से एक पर एंजाइम एमआरएनए को संश्लेषित करता है। एक श्रृंखला में राइबोन्यूक्लियोटाइड्स का संयोजन डीएनए न्यूक्लियोटाइड्स के साथ उनकी पूरकता के अनुपालन में होता है, और डीएनए टेम्पलेट स्ट्रैंड के संबंध में एंटीपैरलल भी होता है। इस तथ्य के कारण कि आरएनए पोलीमरेज़ केवल 5" सिरे से 3" सिरे तक पॉलीन्यूक्लियोटाइड को इकट्ठा करने में सक्षम है, दो डीएनए स्ट्रैंड में से केवल एक, अर्थात् 3" सिरे वाला एंजाइम का सामना करने वाला, एक टेम्पलेट के रूप में काम कर सकता है प्रतिलेखन के लिए (3" → 5")। इस श्रृंखला को कहा जाता है कोडोजेनिक
टीआरएनए- आरएनए, जिसका कार्य अमीनो एसिड को प्रोटीन संश्लेषण स्थल तक पहुंचाना है। टीआरएनए एमिनो एसिड के साथ जटिल होकर - एमआरएनए कोडन में शामिल होकर और एक नए पेप्टाइड बॉन्ड के निर्माण के लिए आवश्यक जटिल संरचना प्रदान करके पॉलीपेप्टाइड श्रृंखला के विस्तार में प्रत्यक्ष भाग लेते हैं।
प्रत्येक अमीनो एसिड का अपना टीआरएनए होता है। टीआरएनए एकल-फंसे हुए आरएनए है, लेकिन इसके कार्यात्मक रूप में इसमें "क्लोवरलीफ़" या "क्लोवरलीफ़" संरचना होती है। अमीनो एसिड प्रत्येक प्रकार के टीआरएनए के लिए विशिष्ट एंजाइम अमीनोएसिल-टीआरएनए सिंथेटेज़ का उपयोग करके अणु के 3" सिरे से सहसंयोजक रूप से जुड़ा होता है। साइट सी पर अमीनो एसिड के अनुरूप एक एंटिकोडन होता है।
(आरआरएनए)- कई आरएनए अणु जो राइबोसोम का आधार बनाते हैं। आरआरएनए का मुख्य कार्य अनुवाद प्रक्रिया को अंजाम देना है - टीआरएनए एडाप्टर अणुओं का उपयोग करके एमआरएनए से जानकारी पढ़ना और टीआरएनए से जुड़े अमीनो एसिड के बीच पेप्टाइड बांड के गठन को उत्प्रेरित करना।
राइबोसोमल आरएनए न केवल राइबोसोम का एक संरचनात्मक घटक हैं, बल्कि एमआरएनए के एक विशिष्ट न्यूक्लियोटाइड अनुक्रम के लिए उनका बंधन भी सुनिश्चित करते हैं। यह पेप्टाइड श्रृंखला के निर्माण के लिए प्रारंभ और रीडिंग फ्रेम स्थापित करता है। इसके अलावा, वे राइबोसोम और टीआरएनए के बीच बातचीत सुनिश्चित करते हैं। राइबोसोम बनाने वाले कई प्रोटीन, आरआरएनए के साथ, संरचनात्मक और एंजाइमेटिक दोनों भूमिकाएँ निभाते हैं।